K-Fold Cross Validation
 By Arijit Roychaudhury
By Arijit RoychaudhuryWell if you are an ML enthusiast then you know that what the value of train-test-split in training a model. So, I will tell in brief about the method train-test-split. In this method, we will simply assign a test size or train size, which takes a huge role in the model selection part. Let, assume train size as 80 percent, that means the model will take 80 percent of itself for training purpose and 20 percent of itself for testing purpose. Now in this manner, the model gets trained. Let’s start learning K-Fold Cross Validation.
But, one drawback we face that at a different time we get different accuracy through this method like we can not expect a fixed accuracy from the model.
So, to get rid of this problem we will get introduced with Cross Validation method.
What is Cross Validation?
In this method, we take several epochs and at each epoch, we take a sample of the data points for testing purposes and take the remaining for training purposes. Now, in the next epoch we take the other part for our testing purpose (no the part that we have already taken for our testing purpose in previous) and the rest for training purpose, and it continues in this way until all epochs get finished.
Now, there are several types of cross validation techniques :
- Leave One Out Cross Validation
- K-Fold Cross Validation
- Stratified Cross Validation
- Time Series Cross Validation
We will discuss here K-Fold Cross Validation only. If you are interested in cross validation, you can research that in google for getting an expert in it.
What is K-Fold Cross Validation?
Now, getting started with an example, as you have already known about cross validation so you will easily understand what K-Fold Cross Validation will be. Now, assume our data-set is of 10,000 sizes like we have 10,000 data points. In , K-fold cross validation we have to pick the K value and after that progress further. Now, in this cross validation method, we will take (datasize/K) amount for our testing purpose and the remaining for our training purpose. In each new epoch, we will consider the same amount of different value for our testing purpose and the remaining for our training purpose. We will continue this process until we complete all epochs.
Now, the question is what will be this (datasize/K) value? Let us take an example, for the previous data-set(10,000 amount of data points) if we consider our K value as 5. Then the process would be something like this below.
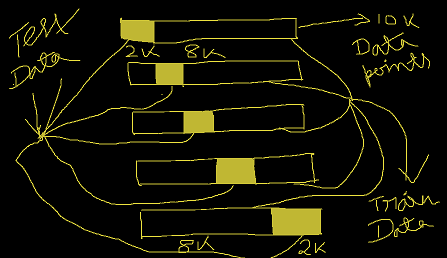
In the above diagram, we can easily see 5 different diagrams due to the K value of 5. In different 5 epochs, we can see how the test data has been varied for different data testing purposes. We will get some different accuracies at different epochs. We just have to compute the arithmetic mean of all the accuracies so that we will get our final desired accuracy. This is how K-Fold Cross Validation works.
K-Fold Cross Validation Code Diagram with scikit-learn
from sklearn import cross_validation # value of K is 5 data_points = cross_validation.KFold(len(train_data_size), n_folds=5, indices=False)
Problem with K-Fold Cross Validation :
In K-Fold CV, we may face trouble with imbalanced data. Now let us see a certain binary classification problem, where we pick some data points for testing purposes at one epoch where all or maximum returns False Output that means we don’t have much Output in True. In that case, the model cannot predict the output True for those data points where the output should be True. This kind of error we can face with K-Cross CV.
So, we have discussed a lot about K-Fold CV. We can omit the problem of K-Fold CV using a Stratified CV. We will discuss that in the next article.
Thanks for reading!!!!!
Also learn:
Leave a Reply