Hierarchical Clustering Analysis
 By Sai Ram
By Sai RamHey guys, today in another data science post we will talk about hierarchical clustering. Let’s have a simple definition of clustering first. Clustering uses techniques that require certain data points on a scatter plot, for instance, to be classified under one class and give them a class label and instances which are the other way around for classification.
Hierarchical Clustering Analysis (HCA)
Let us assume we have a data-points of animals. Each point might represent a different animal. We start with one data point and look for the closest point to it. For example, dog and wolf come under one cluster, tiger and cat come under another cluster based on the properties mentioned in the dataset. Then it builds a dendrogram a hierarchy of clusters.
HCA is of two types
- Agglomerative
- Divisive.
The one we talked about here was the agglomerative technique which is a bottom-up approach.
- Each data point is its own cluster.
- Compute the closest cluster to the current cluster.
- Repeat 2 until we have all clusters under a supercluster.
Dendrograms help us map the clusters. A dendrogram is a hierarchy that shows a relationship among the clusters in the data. Each level describes the sub-cluster and the objects that fall into it. As we said we start from the bottom.
Let’s continue our example with animals. Now when we start with dog and wolf it would be level 1 and a small cluster and then similarly tiger and cat would be another dissimilar but same level cluster which also sits at level 1 and then we proceed with the similarities where the cluster would be a carnivores cluster which is a level 2 cluster and takes some points from level 1 clusters. Now, here we see a pattern the closest the clusters are to each other the more we can classify them and the farther ones would be a unique cluster.
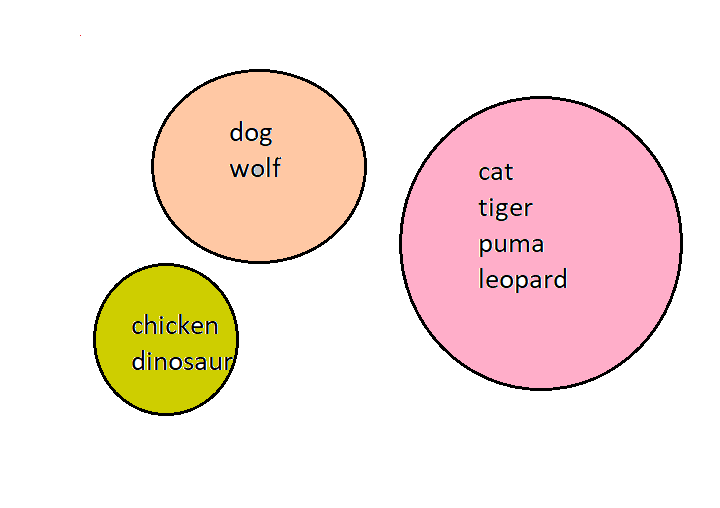
Data points
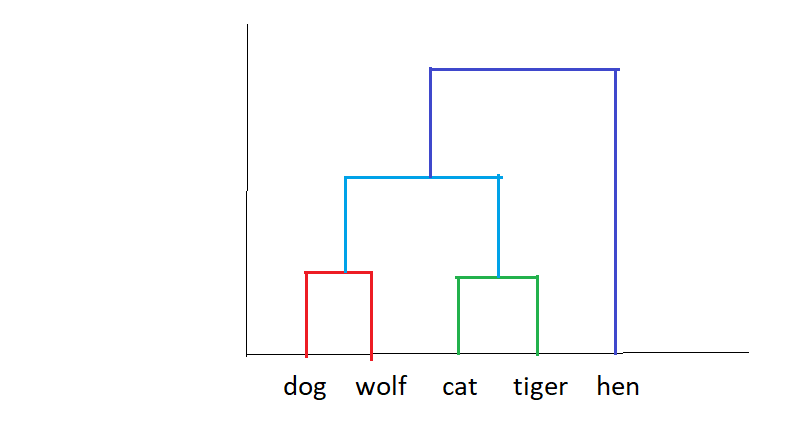
Dendrogram
Calculating distance
We can calculate the cluster distance in four ways
- Minimum – the closest distance between two points
- Maximum – farthest distance between two points
- Average – an average of the distances between two clusters
- Euclidean distance
Space and Time Complexity – HCA
Space Complexity: It requires to store the similarity matrix in the RAM it’s complexity is O(n2).
Time Complexity: Each iteration and updating of the similarity matrix requires O(n3).
Disadvantage of HCA
This algorithm doesn’t work with huge data since it has high space and time complexity.
Also, read- Image Classification in python
Thank you
Leave a Reply