ECLAT Algorithm in Machine Learning
 By Vanshikha Sharma
By Vanshikha SharmaIn this tutorial, Let us discuss the ECLAT Algorithm. ECLAT is short for Equivalence Class Clustering and bottom-up lattice traversal. It is like Apriori Algorithm a method of Association rule mining. Association rule mining is an ML method to find interesting relations between different items. We can say it is a more efficient version of APRIORI. It uses a depth-first search which makes the algorithm more efficient then apriori. As we collect the information about the item rather than the transaction to group similar things it makes this algorithm fast to execute. Before explaining how this algorithm works, let us define some thresholds that will help in deriving the co-relations.
Threshold terms:
- Support: It is a count of how many times an item occurs in a database. Support (XY) = frequency of both items in Database/ Total number of transaction in Database
- Confidence: It is a fraction of record containing X ∪ Y to the total number of records in the database that contains X. It is defined as the strength of the association. Confidence (X|Y) = Support when both items are present / Support of the first item
How does the algorithm work?
In this algorithm, the support value for an item is found to avoid the generation of subset that case below the minimum support. The function verifier each item-transaction set with all other pairs to generate a new candidate. If this candidate is frequent then it is added in the frequent pair list. If items are a pair in the frequency set then it’s subsets are also present in the frequent item set.
Let us see working through an example:
Transition record:
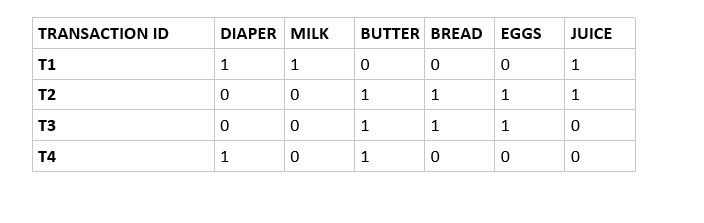
The above transaction records give a boolean representation of what items are brought in all the transactions. Now for the first recursive call minimum support is 2. First, we find the support of a single item.

Now for the second recursive call. We take two items at a time. So here we have combined two-item set to find the following table.
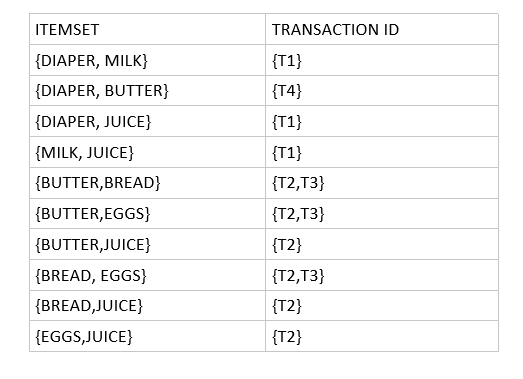
Now for the third recursive call. We now take three items at a time. We take all the triplets that can be found and then the transactions with support less than minimum support is discarded so we get the following transaction table. As no more items can be combined we stop at this.

From this, we can find the following association rules.
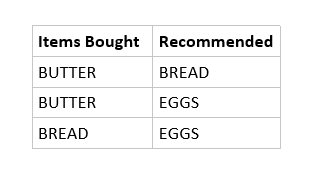
Now, Let’s discuss why this algorithm is efficient.
- It uses less memory as it follows a depth-first search.
- It gives result quicker than APRIORI
- It does not involve repeated scans in the database to find the item or itemset.
In conclusion, We can see how this method is an efficient way of implementing the apriori algorithm. There are many other methods to improve the algorithm like using the hash method, partitioning etc, but this is the most used method.
Leave a Reply