Optimization Techniques : Adaptive Gradient Descent
 By Arijit Roychaudhury
By Arijit RoychaudhuryNow, we will discuss some new optimization techniques that are effective in reducing loss function of our model. The two effective optimization functions are Adaptive Gradient Descent and Adaptive Delta Optimizer. We will discuss the Adaptive Gradient Descent here.
We have discussed three optimization techniques in our previous article. Please do check it below…
Optimization Techniques In Neural Network
What is Adaptive Gradient Descent?
In this optimizer, we can effectively reduce the loss of our model by optimum weight updation. Now, if you remember in the previous article we have discussed the weight updation function.
The function basically is : W(new)= W(old)- (a*(dL/dW(old)))
So,st some layer t function should look like : W(t)= W(t-1)- (a*(dL/dW(t-1)))
Now, in this optimization technique, we will just change the learning rate(a) in an adaptive manner. Well, in a simple way we can say that the learning rate would be different for different layers or for different features or maybe for different neurons.
Methodology of Adaptive Gradient Descent :
So, let us see how this learning rate would be updated in this optimization technique…
For a particular learning rate(a), the new learning rate for the next layer of the neural network would be something like this :
The new learning rate (a(new)) = a/sqrt(k+e)
[sqrt= square root] [e= a small positive value ] [k =sum(dL/dW(i))^2 , i=1…t]
I hope the above equations are clear to you. If not then please check the below image, here you can get understand about the significance of all values.
Hope this helps…
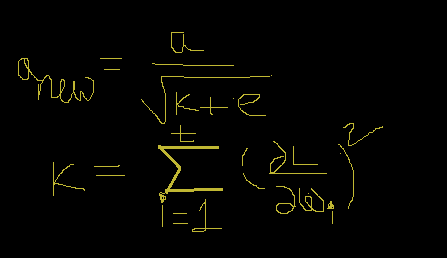
If you see the k value, you can understand that it takes t times calculation. So that we can say with the increment of the t value(the layer of the neural network) we can increase the k value. So, k becomes a large value for some deeper layers. In a reverse way from the equation of the new learning rate( a(new)), we can say that the value of the new learning rate gets decreased with the increment of the k value.
If we take an example :
for t=1 the learning rate =0.90[k value is something fixed]
for t=2 the learning rate =0.85[ k value increases for 2 layers]
for t=3 the learning rate =0.80[k value increases more for 3 layers]
for t=4 the learning rate =0.75 [k value increases more for 4 layers]
So, it is a good fit for our model to get it it’s convergence. Like, the neural network can smoothly converge towards the global minima.
Problem Of Adaptive Gradient Descent :
Now, a very minor problem we may face some time here. The problem is in the above equations you saw that with increasing the number of layers the k value gets increased. So, one time may come for some very deep neural network or some larger data values that this k value becomes a very large value that we can’t handle. So, to prevent this situation we can come up with an idea called the Adaptive Delta method. We will discuss it in the next article.
Leave a Reply