Optimal Value of K in K-Means Clustering in Python | Elbow Method
 By Abuzer Malvi
By Abuzer MalviIn this article, we’ll discuss and illustrate how to find the optimal value of k in the K-Means clustering using the Elbow method in Python.
As we are aware, K-Means follows a way that is simple and easy to classify a given data set through a certain number of clusters k. Although the k value (number of clusters) has to be specified by the user.
So What should be the optimal value of k in the K-Means algorithm?
Apparently, the answer to this question is indefinite. However, the Elbow Method in k -means is most commonly used which somewhat gives us an idea of what the right value of k should be.
Elbow Method
The motive of the partitioning methods is to define clusters such that the total within-cluster sum of square (WSS) is minimized.
The steps to determine k using Elbow method are as follows:
- For, k varying from 1 to let’s say 10, compute the k-means clustering.
- For each k, we calculate the total WSS.
- Plot the graph of WSS w.r.t each k.
- The appropriate number of clusters k is generally considered where a bend (knee) is seen in the plot.
The k from the plot should be chosen such that adding another cluster doesn’t improve the total WSS much.
Now let’s go ahead and see the illustration of the same. Here we will use the own dataset that is generated by the code itself.
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
# Create dataset with 4 random cluster centers and 2000 datapoints
x, y = make_blobs(n_samples = 2000, centers = 4, n_features=2, shuffle=True, random_state=31)
plt.scatter(x[:, 0], x[:, 1], s = 30, color ='b')
# label the axes
plt.xlabel('X')
plt.ylabel('Y')
plt.show()
And below is the resulting plot:
cluster_range = range(1,10)
cluster_wss = []
from sklearn.cluster import KMeans
for num_cluster in cluster_range:
clusters = KMeans(num_cluster)
clusters.fit(x)
cluster_wss.append(clusters.inertia_)
plt.xlabel('# Clusters')
plt.ylabel('WSS')
plt.plot(cluster_range, cluster_wss, marker = 'o')
plt.show()
After we run the code, we can see:
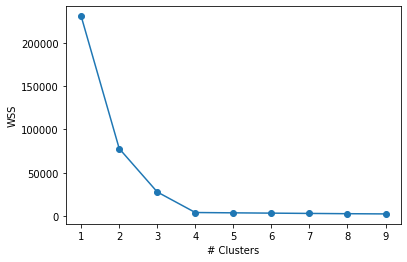
Now we can see that there is not so much decrease in WSS even after we increase the number of clusters beyond 4.
However, here it seemed pretty easy as the data in hand was clearly clustered but that surely is not the case while dealing with real-world data.
Also read,
Leave a Reply