KMeans Clustering in Python
 By Manisha
By ManishaIn this post, you are going to learn how to do KMeans Clustering in Python.
Before starting to write the code, you must know what is KMeans Clustering and why do we use it?
KMeans Clustering is a type of unsupervised clustering where the main aim is to group all those points together which are near to each other, on the basis of the distance they have in between them, in a given dataset. So, KMeans clustering tries to minimize these distances between the points, so that the data can be group neatly.
KMeans Clustering in Python
Step 1
Let us start by importing the basic libraries that we will be requiring
import matplotlib.pyplot as plt import pandas as pd
Here, matplotlib.pyplot is used to import various types of graphs like a line, scatter, bar, histogram, etc.
*I am using pandas to import files that I am going to use, but you can also use NumPy.
Step 2
Now import the file. If you want to use the file I have used, please click here.
data=pd.read_csv('Experiment.csv')
If we see this data, it has three columns: Experiment Name, Result 1 and Result 2. But to perform clustering we only need data of Result 1 and Result 2.
Therefore, now we need to extract these columns into a new variable, say z.
z=data.iloc[:, [1,2]].values
Step 3
Now, once this is done, we will import KMeans.
from sklearn.cluster import KMeans
Step 4
After importing KMeans, we have to decide the number of clusters, you want from your data. The best way to know the ideal number of clusters, we will use Elbow-Method Graph. But, to plot this, we need to calculate Within Cluster Sum of Squares. So, we will make a variable WCSS with square brackets and run a loop. As 10 iterations will suffice this data, we will run the loop for a range of 10.
WCSS=[] for i in range(1,11):
Here, the loop will start from 1 and will continue till it completes 10.
Step 5
Now, we will make a new variable and will fit the values from KMeans to our variable z and also will append the value of WCSS in the loop.
WCSS=[]
for i in range(1,11):
kmeans=KMeans(n_clusters = i, init = 'k-means++', max_iter = 300, n_init = 10, random_state = 0 )
kmeans.fit(z)
WCSS.append(kmeans.inertia_)
n_clusters = number of clusters
init = random method of initialization (to avoid any random initialization trap, we will use k-means++)
max_iter = maximum number of iterations (300 is the default value)
n_init = number of times initialization will run (10 is the default value)
random_state = fixes all random values of KMeans
kmeans.fit will fit all the values of variable kmeans into our variable z.
Step 6
Now, we will plot our Elbow Graph through which we will get to know, what will be a good number of clusters for our data.
plt.plot(range(1,11), WCSS)
plt.savefig('Elbow Method.png')
plt.show()
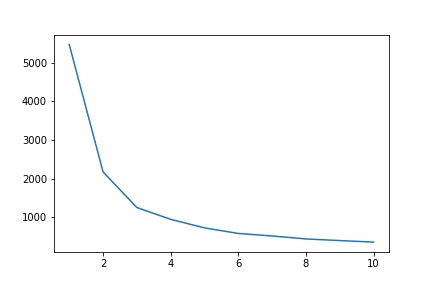
Step 7
After this is done, we know that now the shape of the elbow has given us the ideal number of clusters for our data which is 3.
So, now repeating Step 5, but with the number of clusters as 3
kmeans=KMeans(n_clusters = 3, init = 'k-means++', max_iter = 300, n_init = 10, random_state = 0) y_means=kmeans.fit_predict(z)
kmeans.fit_predict will show the cluster a data point belongs to.
Step 8
Let us now draw a scatter plot to see how our data seems in clusters.
plt.scatter(z[y_means == 0,0],z [y_means==0,1], s=100, c='red') plt.scatter(z[y_means == 1,0],z [y_means==1,1], s=100, c='magenta') plt.scatter(z[y_means == 2,0],z [y_means==2,1], s=100, c='cyan')
s = size of data points
c = color of data points

Step 9
To show the centroids of each cluster
plt.scatter(kmeans.cluster_centers_[: ,0],kmeans.cluster_centers_[:,1], s = 150, c='yellow')

Step 10
Finally, to see the clusters formed in the dataset and saving the figure with labels
plt.xlabel('Result 1')
plt.ylabel('Result 2')
plt.title('Clustering')
plt.savefig('Clustering.png')
plt.show()

Leave a Reply