Multiclass Classification using Scikit-Learn
 By Kunal Gupta
By Kunal GuptaHello everyone, In this tutorial, we’ll be learning about Multiclass Classification using Scikit-Learn machine learning library in Python. Scikit-Learn or sklearn library provides us with many tools that are required in almost every Machine Learning Model. We will work on a Multiclass dataset using various multiclass models provided by sklearn library. Let us start this tutorial with a brief introduction to Multi-Class Classification problems.
Multiclass Classification Problems and an example dataset.
If a dataset contains 3 or more than 3 classes as labels, all are dependent on several features and we have to classify one of these labels as the output, then it is a multiclass classification problem. There are several Multiclass Classification Models like Decision Tree Classifier, KNN Classifier, Naive Bayes Classifier, SVM(Support Vector Machine) and Logistic Regression.
We will take one of such a multiclass classification dataset named Iris. We will use several models on it. It includes 3 categorical Labels of the flower species and a total of 150 samples. These are defined using four features. You can download the dataset here.
You can also fund the iris dataset on the UCI website. The dataset we will work with is in the CSV format.
Now, let us start with the importing and preprocessing part.
Importing and Preprocessing the data
First of all, let’s start by importing and then processing required data:
import pandas as pd import matplotlib.pyplot as plt import seaborn as sns data = pd.read_csv(r'D:\iris.csv') x= data.iloc[:,:-1].values y=data.iloc[:,-1].values from sklearn.preprocessing import LabelEncoder ly = LabelEncoder() y = ly.fit_transform(y)
We have imported the necessary libraries for the preprocessing part. We also have separated the features as x and the labels which are the output as y. Features include sepal_length, sepal_width, petal_length, petal_width, and the target include one of 3 categories ‘setosa’, ‘versicolor’, ‘virginica’.
Let us see the components of data and visualize them by plotting each of the four features one by one in pairs and the species as the target using the seaborn library.

sns.set()
sns.pairplot(data[['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species']],
hue="species", diag_kind="kde")

We have used LabelEncoder() from the sklearn library which will convert all the categorical labels into numeric values. Its time to split our data into the test set and the training set.
Splitting Data using Sklearn
from sklearn.model_selection import train_test_split x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2)
train_test_split() from sklearn library will split our data into the training set and the test set with a ratio of 8:2 as we have defined the test_size of 0.2 means 20% of the data. Now that we have split our data its time to model our data. We will see several models on the same split dataset of different multiclass classifiers.
Gaussian Naive Bayes classifier using Sklearn
Gaussian NB is based on the Naive Bayes theorem with the assumption of conditional independence between every pair of features given the label of the target class. The Graph for the likelihood of the feature vectors is Gaussian.
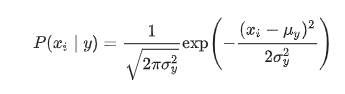
Here, (1/(σ√2Π)) defines the height of the curve, µ is the position of the center of the peak(Mean) and σ is the standard deviation that controls the width of the “bell”. Let us apply Gaussian Naive Bayes on the iris dataset.
from sklearn.naive_bayes import GaussianNB gnb = GaussianNB() gnb.fit(x_train,y_train) y_pred_test = gnb.predict(x_test) from sklearn.metrics import accuracy_score acc = accuracy_score(y_test,y_pred_test)
We have import GaussianNB classifier from sklearn.naive_bayes module, initialize and then fit the training set. Next, because we are interested in checking out the accuracy of our model, We have predicted the model on the test set and compare the predictions with the actual value. In the end, we have imported the accuracy score metric from sklearn library and print the accuracy.
0.9333333333333333
Logistic Regression using Sklearn
Logistic Regression is one of the basic and powerful classifiers used in the machine learning model used for binary as well as multiclass classification problems. You can learn more about Logistics Regression in python. Let us apply logistic regression in the same way as we have applied the GaussianNB on the Iris dataset that we have and will be printing the accuracy score for this model as well.
from sklearn.linear_model import LogisticRegression logreg = LogisticRegression(solver = 'lbfgs',multi_class='auto') logreg.fit(x_train,y_train) y_pred = logreg.predict(x_test) from sklearn.metrics import accuracy_score acc1 = accuracy_score(y_test,y_pred)
We have taken the parameters ‘solver’ as lbfgs because it is good in handling the multinomial loss and ‘multi_class’ as auto which automatically selects between ovr(one-vs-rest) and multinomial. Let us see the accuracy.
0.9333333333333333
Decision tree classifier using sklearn
Decision Tree classifier is a widely used classification technique where several conditions are put on the dataset in a hierarchical manner until the data corresponding to the labels is purely separated. Learn more about Decision Tree Regression in Python using scikit learn. Its time to apply the decision tree on the iris dataset and check the accuracy score.
from sklearn.tree import DecisionTreeClassifier dt = DecisionTreeClassifier() dt.fit(x_train,y_train) y_pred2 = dt.predict(x_test) acc2 = accuracy_score(y_test,y_pred2)
0.9333333333333333
KNN (k-nearest neighbors) classifier using Sklearn
KNN classifier is a very simple technique for classification and it is based upon the Euclidean distance between two data points calculated by taking the distance between the feature vector.
In case of the same distance between a data point and data points belonging to two or more different classes then, the next lowest distance is calculated and it is assumed that the data point will belong to that class. The formula to calculate Euclidean distance between two data points is:
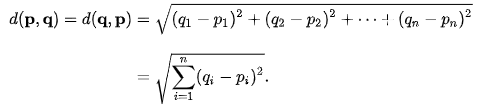
Let us apply the KNN classifier using the Sklearn library and check the accuracy score.
from sklearn.neighbors import KNeighborsClassifier clf = KNeighborsClassifier(n_neighbors=3,algorithm='ball_tree') clf.fit(x_train,y_train) y_pred3 = clf.predict(x_test) acc3 = accuracy_score(y_test,y_pred3)
0.9666666666666667
Support Vector Machine using Sklearn
Support Vector Machine or SVM is a classifier that classifies the data points into the classes(Supervised Learning) and separates those classes using a hyperplane. Learn more about SVM in the Support vector machine(SVM) tutorial. So, like always we want to apply SVM to our Iris dataset and check the accuracy of the model.
from sklearn.svm import SVC svc1 = SVC(C=50,kernel='rbf',gamma=1) svc1.fit(x_train,y_train) y_pred4 = svc1.predict(x_test) from sklearn.metrics import accuracy_score acc4= accuracy_score(y_test,y_pred4)
0.9333333333333333
We hope you like this tutorial and understood how to implement Multiclass Classification using Scikit-Learn machine learning Python library. If you have any doubts, feel free to ask in the comment section below.
You may like to read the articles given below:
- Implementation of Random Forest for classification in python
- Binary Classification using Neural Networks
- Naive Bayes Algorithm in Python
Leave a Reply