Build Recommender Systems with Movielens Dataset in Python
 By Yash Gandhi
By Yash GandhiHere, we learn about the recommender system and its different types. We learn to implementation of recommender system in Python with Movielens dataset.
What is the recommender system?
The recommendation system is a statistical algorithm or program that observes the user’s interest and predict the rating or liking of the user for some specific entity based on his similar entity interest or liking. Recommendation system used in various places. YouTube is used for video recommendation. Netflix using for shows and web series recommendation. Amazon and other e-commerce sites use for product recommendation. Face book and Instagram use for the post that users may like. There is another application of the recommender system.
Different type of recommender system
There is mainly two types of recommender system.
- Content-based
This recommendation is based on a similar feature of different entities. If someone likes the movie Iron man then it recommends The avengers because both are from marvel, similar genres, similar actors. Recommender systems can extract similar features from a different entity for example, in movie recommendation can be based on featured actor, genres, music, director.
- Collaborative filtering
Collaborative filtering recommends the user based on the preference of other users. There are two different methods of collaborative filtering.
-
- Model-based
- Memory-based
- Model-based
A model-based collaborative filtering recommendation system uses a model to predict that the user will like the recommendation or not using previous data as a dataset.
- Memory-based
In memory-based collaborative filtering recommendation based on its previous data of preference of users and recommend that to other users.
Dataset: Movielens
Here, we use the dataset of Movielens. It contains 100,000 ratings and 3600 tag application to 9000 movies by 600 users. You can download the dataset here: ml-latest dataset
Implementing Recommendation System
Here, we are implementing a simple movie recommendation system. The system is a content-based recommendation system.
First, importing libraries of Python. Pandas, Numpy are used in this recommendation system.
import numpy as np import pandas as pd
Loading and merging the movie data from the .csv file.
movie_data=pd.read_csv('ratings.csv')
movie_data.head(10)
Output:-

movies=pd.read_csv('movies.csv')
movies.head(10)
Output:-
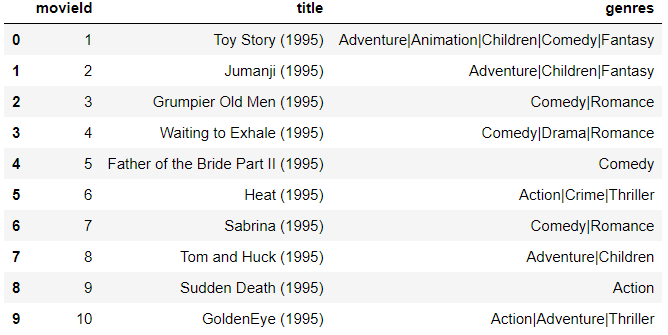
tags=pd.read_csv('tags.csv')
tags=tags[['movieId','tag']]
tags.head(10)
Output:-
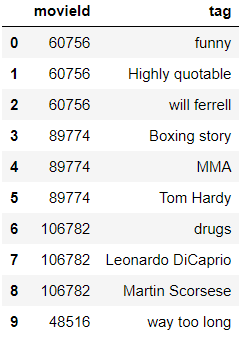
movie_data=movie_data.merge(movies,on='movieId',how='left') movie_data=movie_data.merge(tags,on='movieId',how='left') movie_data.head(10)
Output:-
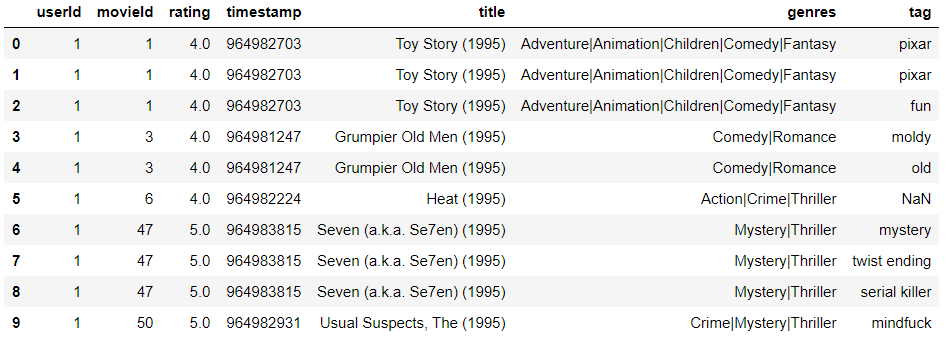
Now we averaging the rating of each movie by calling function mean().
rating = pd.DataFrame(movie_data.groupby('title')['rating'].mean())
rating.head(10)
Output:-
![rating = pd.DataFrame(movie_data.groupby('title')['rating'].mean())](https://www.codespeedy.com/wp-content/uploads/2020/04/O5-1.png)
How many users give a rating to a particular movie. So, we also need to consider the total number of the rating given to each movie
rating['Total Rating']=pd.DataFrame(movie_data.groupby('title')['rating'].count())
rating.head(10)
Output:-
![rating = pd.DataFrame(movie_data.groupby('title')['rating'].mean())](https://www.codespeedy.com/wp-content/uploads/2020/04/O6-1.png)
Now we calculate the correlation between data. Here we correlating users with the rating given by users to a particular movie. Here we create a matrix that represents the correlation between user and movie.
movie_user=movie_data.pivot_table(index='userId',columns='title',values='rating') movie_user.head(10)
Output:-

Now, we can choose any movie to test our recommender system. Here, I selected Iron Man (2008). For finding a correlation with other movies we are using function corrwith(). This function calculates the correlation of the movie with every movie.
correlation=movie_user.corrwith(movie_user['Iron Man (2008)']) correlation.head(10)
Output:-

In our data, there are many empty values. So first we remove all empty values and then joining the total rating with our data table.
recommandation=pd.DataFrame(correlation,columns=['correlation']) recommandation.dropna(inplace=True) recommandation=recommandation.join(rating['Total Rating']) recommandation.head()
Output:-
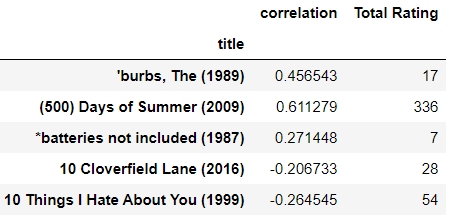
Now for making the system better, we are only selecting the movie that has at least 100 ratings. We also merging genres for verifying our system.
recc=recommandation[recommandation['Total Rating']>150].sort_values('correlation',ascending=False).reset_index()
recc=recc.merge(movies,on='title',how='left')
recc.head(10)
Output:-
![recc=recommandation[recommandation['Total Rating']>150].sort_values('correlation',ascending=False).reset_index()](https://www.codespeedy.com/wp-content/uploads/2020/04/O10-1.png)
We can see that the top-recommended movie is Avengers: Infinity War. As we know this movie is highly correlated with movie Iron Man. So we can say that our recommender system is working well.
Conclusion
We learn that
- What is the recommender system?
- Different types of recommender systems.
- Implementation of the recommended system in Python
Also read: How to track Google trends in Python using Pytrends
Leave a Reply