Support Vector Machines for classification of data
 By Sai Ram
By Sai RamClassification is an important ingredient in data science. Before we go to classification in kernel SVM let’s analyze the basics.
What exactly is classification?
For instance, your client might require predicting if young people prefer Netflix or Anime more. Your dataset will have attributes and parameters corresponding to a certain attribute based on age, gender and name. Of course, this might all seem irrelevant to you but it’s the breadwinner of the client. Nevertheless, when you put your feet in the data science field it’s not only about prediction it’s about rules of how a model works and how well it works on linear data and non-linear data.
Now, our data is clearly non-linear data. Because a parameter or a feature is not varying linearly with your dependant output. I presume you have a good understanding of regression analysis with linear data and polynomial regression. If not check out linear regression then polynomial regression.
I recommend Statquest’s videos.
For now, the reason we don’t prefer polynomial regression is that it cannot choose a proper degree for a correct bias-variance tradeoff.
Now the topic here we want to discuss is SVM.
Classification using Kernel SVM
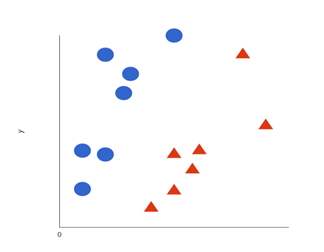
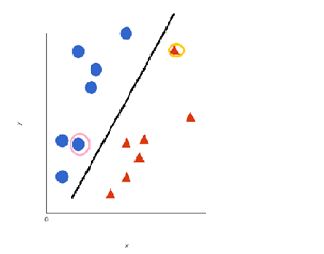
What is SVM?
Now the data we see here is clearly different. Yes, you are right. After closely observing there is no line ( an ordinary least squares ) passing through the points if it does then you’re having a bias-variance problem. Now we fit a line between those boundaries. As we see there are two near points to the line these are called support vectors. This line is called ‘decision boundary/hyper plane’ this plane rather than minimizing the features it limits the threshold i.e, it selects values by limiting threshold. This plane transforms 2d data into 3d data that is into a higher dimension.
This is computationally expensive but there is a trick.
To do this there is a kernel trick. It is a function that takes
- Input : vectors in original space
- Output : dot product in feature space.
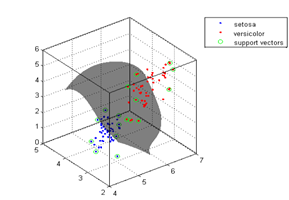
So all the points are now in higher dimension basically looking like this.
This is kernel trick.
# Kernel SVM preprocessing the data in R.
# Importing the dataset
dataset = read.csv('Social_Network_Ads.csv')
dataset = dataset[3:5]
# Encoding the target feature as factor
dataset$Purchased = factor(dataset$Purchased, levels = c(0, 1))
# Splitting the dataset into the Training set and Test set
# install.packages('caTools')
library(caTools)
set.seed(123)
split = sample.split(dataset$Purchased, SplitRatio = 0.75)
training_set = subset(dataset, split == TRUE)
test_set = subset(dataset, split == FALSE)
You can refer to an example
Leave a Reply