SMOTE and Near Miss in Python for imbalanced datasets
 By Sumit Singh
By Sumit SinghIn this tutorial, we shall learn about dealing with imbalanced datasets with the help of SMOTE and Near Miss techniques in Python.
Let’s first understand what imbalanced dataset means
Suppose in a dataset the examples are biased towards one of the classes, this type of dataset is called an imbalanced dataset.
Let’s take an example for a better understanding:
Imagine a class of 100 students where 90 are boys and only 10 are girls. In an ideal situation, one would think of a ratio of around 1/2 each. Here the girls fall in minority class whereas the boys in the majority.
In such condition any results received will be highly dependent on the boys. Hence this is an example where data is biased towards the boys.
It is clear from above that problem occurs in the classification of the dataset in the various classes. The issue is that classification algorithms are based on an assumption. The assumption is that there exists an equal number of examples for each class.
To tackle this issue we shall somehow try to bring the classes on an equal number of examples.
SMOTE (Synthetic Minority Over-Sampling Technique)
SMOTE tries over-sampling of the minority class in the dataset. It tries to create duplicate copies of minority class to match with the majority one. This shall be applied before fitting the model.
Near Miss Technique
It is just the opposite of SMOTE. It tries under-sampling and brings the majority class down to the minority.
Using SMOTE on imbalanced datasets
Let’s now see the application through python:
Let me use a sample of 1000 points (0’s and 1’s) in which the data is biased towards one of the two. We shall first use the make_classification function to set the values for two classes and set the weight of one class to 0.95 and that of other 0.05. Then, we use the matplot.lib to plot the points going over all of them using a ‘for’ loop.
from numpy import where import matplotlib.pyplot as pyplot from collections import Counter from sklearn.datasets import make_classification from imblearn.over_sampling import SMOTE from imblearn.under_sampling import NearMiss Xsmote, Ysmote = make_classification(n_samples=1000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.95], flip_y=0, random_state=1) count = Counter(Ysmote) print(count) for label, i in counter.items(): row_ix = where(Ysmote == label)[0] pyplot.scatter(Xsmote[row_ix, 0], Xsmote[row_ix, 1], label=str(label)) pyplot.legend() pyplot.show()
Output:
Counter({0: 950, 1: 50})
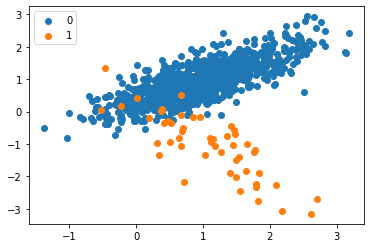
Now let us apply SMOTE to this dataset:
os = SMOTE() Xsmote, Ysmote = os.fit_resample(Xsmote, Ysmote) count = Counter(Ysmote) print(count) for label, i in counter.items(): row_ix = where(Ysmote == label)[0] pyplot.scatter(Xsmote[row_ix, 0], Xsmote[row_ix, 1], label=str(label)) pyplot.legend() pyplot.show()
Here we use the SMOTE function and store new values inside the variables and then again plot the points.
Output:
The output received after applying the SMOTE technique.
Counter({0: 950, 1: 950})
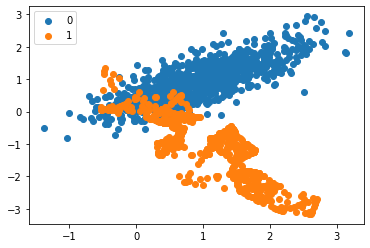
The difference can be seen by the plot and also by the count. The count has changed from 950:50 to 950:950 after SMOTE was used. As mentioned above SMOTE tried duplicating minority class to match with the majority.
Using the Near Miss method on imbalanced datasets
Now, let’s use the same example taken above and try to resolve the issue using the Near Miss technique.
Xnear_miss, Ynear_miss = make_classification(n_samples=1000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.95], flip_y=0, random_state=1) us = NearMiss(version=1, n_neighbors=3) Xnear_miss, Ynear_miss = us.fit_resample(Xnear_miss, Ynear_miss) count = Counter(Ynear_miss) print(count) for label, _ in count.items(): row_ix = where(Ynear_miss == label)[0] pyplot.scatter(Xnear_miss[row_ix, 0], Xnear_miss[row_ix, 1], label=str(label)) pyplot.legend() pyplot.show()
Set the values used in the above example. Here, we use the NearMiss function to scale the majority class down and hence update the value of variables. Then, we use the ‘for’ loop and plot the points.
Output:
Counter({0: 50, 1: 50})

The difference can be seen by the plot and also by count. The count has changed from 950:50 to 50:50. The NearMiss function has successfully brought the majority class down to the minority by undersampling.
So with the help of these two techniques, we can handle the imbalanced data with ease.
Also read: Human Activity Recognition using Smartphone Dataset- ML Python
Leave a Reply