Predicting next number in a sequence with Scikit-Learn in Python
 By Snigdha Ranjith
By Snigdha RanjithIn this post, we will see how to predict the next set of numbers in a sequence with Scikit-learn in Python. We are using linear regression to solve this problem.
To put things simply, we try to fit a straight line through the sequence of numbers and predict the further set of numbers by finding the y-coordinates to their corresponding x-coordinates. For this, we will use the python machine learning library Scikit-Learn. Along with sklearn, we will also use numpy and matplotlib libraries. Since we are working with a small dataset, we are not importing pandas. But, if you are working with a large dataset, you can also work with pandas dataframes instead of numpy arrays.
So, let’s get started!
Importing libraries to predict next number in a sequence with Scikit-Learn
import numpy as np import matplotlib.pyplot as plt from sklearn.linear_model import LinearRegression
Firstly, import numpy, matplotlib, and sklearn. In sklearn, we will only need the LinearRegression package. Ensure you have Scikit-Learn library installed on your PC.
Getting data
In this section, we will take a random sequence of data in a 2D list. The first column is the serial number of a particular number in the sequence and the second column is the sequence itself.
data =\ [ [0, 1], [1, 8], [2, 13], [3, 16], [4, 20], ]
Then we convert this list into two arrays, X and y using numpy array() method. Here, X = independent variable and y = dependent variable. The reshape(-1,1) converts the array from [0 1 2 3] to [[0] [1] [2] [3]] i.e. from shape(1,n) to shape(n,1).
X = np.array(data)[:,0].reshape(-1,1)
y = np.array(data)[:,1].reshape(-1,1)
print("X=")
print(X)
print("y=")
print(y)
Output:
X= [[0] [1] [2] [3] [4]] y= [[ 1] [ 8] [13] [16] [20]]
Thus, we have stored our sequence of numbers in y and the position of the number in X.
Note: You can also make use of pandas dataframe here to get the two columns.
Before we move on to the next section, we also have to define the position of the next set of numbers we want to predict. For this, we define a variable to_predict_x and convert it to a numpy array. It stores the x-coordinates(position) of the next set of numbers.
to_predict_x= [5,6,7] to_predict_x= np.array(to_predict_x).reshape(-1,1)
Prediction values
To predict the next values of the sequence, we first need to fit a straight line to the given set of inputs (X,y). the line is of the form “y=m*x +c” where, m= slope and c= y_intercept.
To do this, we will use the LinearRegression() method from sklearn library and create a regressor object. We then call the fit() method on the regressor object and pass the parameters X and y. The fit() method is used to train our program and basically come up with a straight line that fits our data.
regsr=LinearRegression() regsr.fit(X,y)
Now, we can predict the values for a given position by passing the “to_predict_x” variable to the predict() method. This will predict the y-values for the given x-values using the extrapolation method. We can also get the slope(m) and y-intercept(c) of the fitted line.
predicted_y= regsr.predict(to_predict_x)
m= regsr.coef_
c= regsr.intercept_
print("Predicted y:\n",predicted_y)
print("slope (m): ",m)
print("y-intercept (c): ",c)
Output:
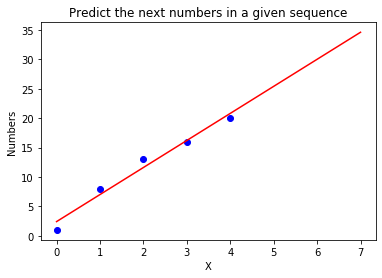
If we want to see how the line that we fitted to the inputs look, type the following code to generate the graph:
import matplotlib.pyplot as plt
%matplotlib inline
plt.title('Predict the next numbers in a given sequence')
plt.xlabel('X')
plt.ylabel('Numbers')
plt.scatter(X,y,color="blue")
new_y=[ m*i+c for i in np.append(X,to_predict_x)]
new_y=np.array(new_y).reshape(-1,1)
plt.plot(np.append(X,to_predict_x),new_y,color="red")
plt.show()
Here, the new_y variable stores the y values of the fitted line including the extrapolated part.
Output:
To know more about the awesome and extremely easy Scikit-Learn library visit its documentation page.
See more programs using Scikit-Learn like:
Decision Tree Regression in Python using scikit learn
can I use this model for predicting next number 1 or 2 by feeding past data as input?
I think there’s a typo in section *Getting data*, second paragraph. The present call of reshape(-1,1) does not convert from shape (1,n) to shape (n,1), but from shape (n,) to shape (n,1).
Hi, I´m trying to implement this solution into predict a sequence of 6 numbers based on an input of 100 rows on a CSV file, like this:
Training data (100 rows):
row 1: [10, 45, 56, 12, 6, 40]
…..
row 100: [11, 20, 5, 17, 78, 23]
Predict the next sequence (101 row): […, …, …, …, …, … ]
But your code only takes a one column array and I don´t know how to handle the data,
Any help will be really appreciated
Did you manage to handle the data with more than one column?