Outlier detection from Inter-Quartile Range in Machine Learning | Python
 By Aumkar M Gadekar
By Aumkar M GadekarOutlier detection is an important part of many machine learning problems. The quality and performance of a machine learning model depend on the quality of the data. However, datasets often contain bad samples, noisy points, or outliers.
What exactly is an outlier? Outliers are points that don’t fit well with the rest of the data. For example, see the regression line below. This represents the data X=[1,2,3,4,5,6,7,8])
and Y=[3.1, 6.7, 8.5, 12.5, 13, 18.8, 21, 24.4].
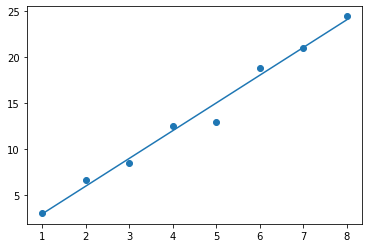
The linear regression appears to suit the data well, with little error. Therefore, the model is a good fit. Now suppose we introduce two points as outliers : (9, 57) and (10,112). These two coordinates do not have the same linearity as the previous points. Hence we can see that adding the two outliers greatly disrupts the regression results.

Therefore, outlier detection and removal is of importance for better accuracy of our model.
What is InterQuartile Range?
This is a very simple technique that makes use of statistical measures. If you have studied boxplots, you would be aware of what the terms median, percentile, and quartile range mean. Boxplots show the distribution of data. A quartile measures every 25th percent of the total data points. The first quartile means the 25th percentile of values, the second is the median or 50th percentile, and the 3rd and fourth quartile represents the 75th and the 100th percentile(maximum value), respectively. As such, the distance between the first and third quartile represents the range of the middle 50 percent values, called the interquartile range.
The method for finding outliers is simple. We find out the interquartile range and choose a multiplier, k, typically equal to 1.5. Then, the range of values lying beyond Q3 + K*IQR and below Q1 – K*IQR are considered to be outliers.
Let us demonstrate this with an example. We use a small dataset for ease of understanding.
Solved Example
Look at the Python code example given below:
X=np.array([0.5,1,4,4,5.5,5.7,5.8,5.9,6,6.3,6.5,6.5,7,7.1,7.2,7.5,8.5,9,9.1,11,12]) l=len(X) Y=[1 for i in range(l)] plt.boxplot(X) plt.scatter(Y,X)

Here, we have generated the dataset and visualized the data points using a scatter plot and boxplot. The boxplot can give information about the data distribution. The ‘box’ in the box plot encloses the interquartile range, with the middle line denoting the median, and the other two lines denoting the lower and upper quartiles. The other two lines at the extremities of the boxplot are the whiskers of the plot. The whiskers denote the cut-off point for outliers.
We can also get the exact mathematical values using NumPy’s quantile function.
print(np.quantile(X,0.25)) print(np.quantile(X,0.50)) print(np.quantile(X,0.75)) >>> 5.7 >>> 6.5 >>> 7.5
Thus we have the median as well as lower and upper quartile. The IQR or inter-quartile range is = 7.5 – 5.7 = 1.8.
Therefore, keeping a k-value of 1.5, we classify all values over 7.5+k*IQR and under 5.7-k*IQR as outliers. Hence, the upper bound is 10.2, and the lower bound is 3.0. Therefore, we can now identify the outliers as points 0.5, 1, 11, and 12. Thus, these points, which do not relate well with the rest of the dataset, can be scraped.
Thus, we have seen a simple technique for anomaly detection.
Leave a Reply