Music Recommendation System Project using Python
 By Neelesh Biswas
By Neelesh BiswasIn this tutorial, we will learn how to create a music recommendation system project using Python.
Nowadays, we all use online music streaming services like Spotify, ITunes, Jio Saavn, Gaana, etc. Do you wonder while playing songs on these platforms, how you get song recommendations from them according to your choice??? This is because these services use machine learning models to give you the songs they think you will listen to. In this article, we’ll be dealing with such models & build a music recommendation system using these models.
Models for recommendation
As I’ve said, these music streaming services use ML models by which they deliver you the songs you like to listen to. These models are defined as classes in a Python package named Recommendation. In this package, we’ll need to import Pandas & Numpy libraries:
import numpy as np import pandas
Now let’s discuss the models which are used for recommendation:
Popularity Recommendation:
This model is used to recommend you songs which are popular or say, trending in your region. Basically this model works based by the songs which are popular among your region or listened by almost every user in the system.
Given below is the source code of popularity recommendation:
class popularity_recommender():
def __init__(self):
self.t_data = None
self.u_id = None #ID of the user
self.i_id = None #ID of Song the user is listening to
self.pop_recommendations = None #getting popularity recommendations according to that
#Create the system model
def create_p(self, t_data, u_id, i_id):
self.t_data = t_data
self.u_id = u_id
self.i_id = i_id
#Get the no. of times each song has been listened as recommendation score
t_data_grouped = t_data.groupby([self.i_id]).agg({self.u_id: 'count'}).reset_index()
t_data_grouped.rename(columns = {'user_id': 'score'},inplace=True)
#Sort the songs based upon recommendation score
t_data_sort = t_data_grouped.sort_values(['score', self.i_id], ascending = [0,1])
#Generate a recommendation rank based upon score
t_data_sort['Rank'] = t_data_sort['score'].rank(ascending=0, method='first')
#Get the top 10 recommendations
self.pop_recommendations = t_data_sort.head(10)
#Use the system model to give recommendations
def recommend_p(self, u_id):
u_recommendations = self.pop_recommendations
#Add user_id column for which the recommended songs are generated
u_recommendations['user_id'] = u_id
#Bring user_id column to the front
cols = u_recommendations.columns.tolist()
cols = cols[-1:] + cols[:-1]
u_recommendations = u_recommendations[cols]
return u_recommendations
Similarity Recommendation:
This model works according to the songs you listen to everyday.
For example: Suppose you listen to the song Numb by Linkin Park on Spotify. After listening to the song, you’ll get song suggestions like: Linkin Park’s In the End or Green Day’s Boulevard of Broken Dreams; since the songs have one thing in common: Artist or Genre.
#Class for Item similarity based Recommender System model
class similarity_recommender():
def __init__(self):
self.t_data = None
self.u_id = None
self.i_id = None
self.co_matrix = None
self.songs_dic = None
self.rev_songs_dic = None
self.i_similarity_recommendations = None
#Get unique songs corresponding to a given user
def get_u_items(self, u):
u_data = self.t_data[self.t_data[self.u_id] == u]
u_items = list(u_data[self.i_id].unique())
return u_items
#Get unique users for a given song
def get_i_users(self, i):
i_data = self.t_data[self.t_data[self.i_id] == i]
i_users = set(i_data[self.u_id].unique())
return i_users
#Get unique songs in the training data
def get_all_items_t_data(self):
all_items = list(self.t_data[self.i_id].unique())
return all_items
#Construct cooccurence matrix
def construct_co_matrix(self, u_songs, a_songs):
#Get users for all songs in user_songs.
u_songs_users = []
for i in range(0, len(u_songs)):
u_songs_users.append(self.get_i_users(u_songs[i]))
#Initialize the item cooccurence matrix of size len(user_songs) X len(songs)
co_matrix = np.matrix(np.zeros(shape=(len(u_songs), len(a_songs))), float)
#Calculate similarity between songs listened by the user and all unique songs in the training data
for i in range(0,len(a_songs)):
#Calculate unique listeners (users) of song (item) i
songs_i_data = self.t_data[self.t_data[self.i_id] == a_songs[i]]
users_i = set(songs_i_data[self.u_id].unique())
for j in range(0,len(u_songs)):
#Get unique listeners (users) of song (item) j
users_j = u_songs_users[j]
#Calculate the songs which are in common listened by users i & j
users_intersection = users_i.intersection(users_j)
#Calculate cooccurence_matrix[i,j] as Jaccard Index
if len(users_intersection) != 0:
#Calculate all the songs listened by i & j
users_union = users_i.union(users_j)
co_matrix[j,i] = float(len(users_intersection))/float(len(users_union))
else:
co_matrix[j,i] = 0
return co_matrix
#Use the cooccurence matrix to make top recommendations
def generate_top_r(self, user, cooccurence_matrix, a_songs, u_songs):
print("Non zero values in cooccurence_matrix :%d" % np.count_nonzero(cooccurence_matrix))
#Calculate the average of the scores in the cooccurence matrix for all songs listened by the user.
user_sim_scores = cooccurence_matrix.sum(axis=0)/float(cooccurence_matrix.shape[0])
user_sim_scores = np.array(user_sim_scores)[0].tolist()
#Sort the indices of user_sim_scores based upon their value also maintain the corresponding score
s_index = sorted(((e,i) for i,e in enumerate(list(user_sim_scores))), reverse=True)
#Create a dataframe from the following
columns = ['user_id', 'song', 'score', 'rank']
#index = np.arange(1) # array of numbers for the number of samples
df1 = pandas.DataFrame(columns=columns)
#Fill the dataframe with top 10 songs
rank = 1
for i in range(0,len(s_index)):
if ~np.isnan(s_index[i][0]) and a_songs[s_index[i][1]] not in u_songs and rank <= 10:
df1.loc[len(df1)]=[user,a_songs[s_index[i][1]],s_index[i][0],rank]
rank = rank+1
#Handle the case where there are no recommendations
if df1.shape[0] == 0:
print("The current user don't have any song for similarity based recommendation model.")
return -1
else:
return df1
#Create the system model
def create_s(self, t_data, u_id, i_id):
self.t_data = t_data
self.u_id = u_id
self.i_id = i_id
#Use the model to make recommendations
def recommend_s(self, u):
#A. Get all unique songs for this user
u_songs = self.get_u_items(u)
print("No. of songs for the user: %d" % len(u_songs))
#B. Get all the songs in the data
a_songs = self.get_all_items_t_data()
print("No. of songs in the list: %d" % len(a_songs))
#C. Make the cooccurence matrix of size len(user_songs) X len(songs)
co_matrix = self.construct_co_matrix(u_songs, a_songs)
#D. Use the matrix to make recommended songs
df_r = self.generate_top_r(u, co_matrix, a_songs, u_songs)
return df_r
#Create a function to get similar songs
def similar_items(self, i_list):
u_songs = i_list
#A. Get all the songs from the data
a_songs = self.get_all_items_t_data()
print("no. of unique songs in the set: %d" % len(a_songs))
#B. Make the cooccurence matrix of size len(user_songs) X len(songs)
co_matrix = self.construct_co_matrix(u_songs, a_songs)
#C. Use the matrix to make recommendations
u = ""
df_r = self.generate_top_r(u, co_matrix, a_songs, u_songs)
return df_r
Now using the Recommendation package along with relevant python libraries, we import them in a new file:
import pandas from sklearn.model_selection import train_test_split import numpy as np import time import Recommenders as Recommenders
After that, we’ll load the data from a given .csv file & retrieve the no. of times a user listens to a song in rows of five:
#Read user_id, song_id, listen_count #This step might take time to download data from external sources triplets = 'https://static.turi.com/datasets/millionsong/10000.txt' songs_metadata = 'https://static.turi.com/datasets/millionsong/song_data.csv' song_df_a = pandas.read_table(triplets,header=None) song_df_a.columns = ['user_id', 'song_id', 'listen_count'] #Read song metadata song_df_b = pandas.read_csv(songs_metadata) #Merge the two dataframes above to create input dataframe for recommender systems song_df1 = pandas.merge(song_df_a, song_df_b.drop_duplicates(['song_id']), on="song_id", how="left") song_df1.head()
Output:

Now we’ll display the no. of songs contained i.e., no of rows contained in the dataset in the file for our better understanding.
print("Total no of songs:",len(song_df1))
Output:
Total no of songs: 2000000
Next, we’ll create a dataframe which will be a subset of the given dataset:
song_df1 = song_df1.head(10000) #Merge song title and artist_name columns to make a new column song_df1['song'] = song_df1['title'].map(str) + " - " + song_df1['artist_name']
The column listen_count denotes the no of times the song has been listened. Using this column, we’ll find the dataframe consisting of popular songs:
song_gr = song_df1.groupby(['song']).agg({'listen_count': 'count'}).reset_index()
grouped_sum = song_gr['listen_count'].sum()
song_gr['percentage'] = song_gr['listen_count'].div(grouped_sum)*100
song_gr.sort_values(['listen_count', 'song'], ascending = [0,1])
A part of the Output I’ve displayed below as it is too long to display:

Below code is the no. of unique users contained in the dataset:
u = song_df1['user_id'].unique()
print("The no. of unique users:", len(u))
Output:
The no. of unique users: 365
Now, we define a dataframe train which will create a song recommender:
train, test_data = train_test_split(song_df, test_size = 0.20, random_state=0) print(train.head(5))
Output:

Creating Popularity based Music Recommendation in Python:
Using popularity_recommender class we made in Recommendation package, we create the list given below:
pm = Recommenders.popularity_recommender() #create an instance of the class pm.create(train, 'user_id', 'song') user_id1 = u[5] #Recommended songs list for a user pm.recommend(user_id1)
Output:
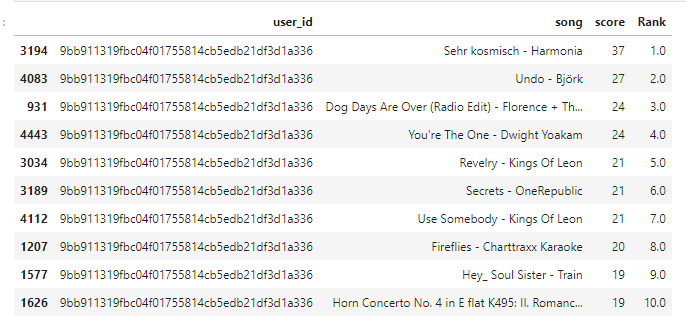
In the above code snippet, user_id1 represents the list of popular songs recommended to the user. We will include the same for user_id2 being the list for another user.
user_id2 = u[8] pm.recommend(user_id2)
Output:

Creating Similarity based Music Recommendation in Python:
As we built the system for popularity recommendation, we will do the same according to the songs listened by the users user_id1 & user_id2 using similarity_recommender class from the Recommendation package. First, we create an instance of the package, after that we proceed for making the list:
is_model = Recommenders.similarity_recommender() is_model.create(train, 'user_id', 'song')
a) for first user (user_id1):
#Print the songs for the user
user_id1 = u[5]
user_items1 = is_model.get_user_items(user_id1)
print("------------------------------------------------------------------------------------")
print("Songs played by first user %s:" % user_id1)
print("------------------------------------------------------------------------------------")
for user_item in user_items1:
print(user_item)
print("----------------------------------------------------------------------")
print("Similar songs recommended for the first user:")
print("----------------------------------------------------------------------")
#Recommend songs for the user using personalized model
is_model.recommend(user_id1)
Output:

b) for second user (user_id2):
user_id2 = u[7]
#Fill in the code here
user_items2 = is_model.get_user_items(user_id2)
print("------------------------------------------------------------------------------------")
print("Songs played by second user %s:" % user_id2)
print("------------------------------------------------------------------------------------")
for user_item in user_items2:
print(user_item)
print("----------------------------------------------------------------------")
print("Similar songs recommended for the second user:")
print("----------------------------------------------------------------------")
#Recommend songs for the user using personalized model
is_model.recommend(user_id2)
Output:
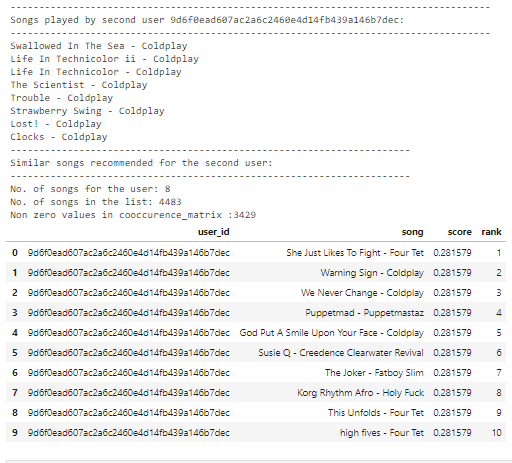
Observations: The lists of both the users in popularity based recommendation is the same but different in case of similarity-based recommendation. This is because the former recommends the list which is popular among a region or worldwide but the latter recommends the list similar to the choices of the user.
NOTE: We can use the system by entering the name of the song keeping in mind that, the name of the song should be included in the given .csv file:
is_model.similar_items(['U Smile - Justin Bieber'])
Output:
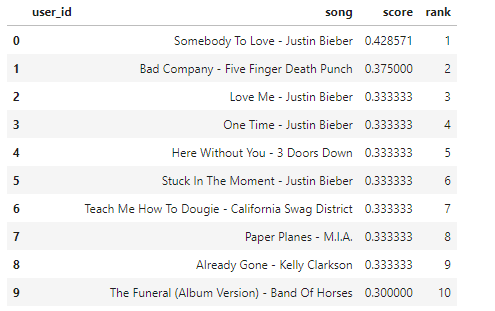
I am not able to find the data set used. can you please provide the link or the Data set
import Recommenders as Recommenders
i have tried every way possible… but i dont think so that this Recommender will work.
I have tried on my jupyter, online jupyter, install the module but doesnt work for me.
If it is working then please tell me that how do you manage to do that.
I’m not getting the final similar song list in the similarity model of recommendation.
when i try to run this
import Recommendations as Recmmenders
i am getting error as no module named “Recommendation”
eventhough i install recommendation package
check if your Recommendations package is not inside other directory.
Had the same problem and instead of
“import Recommenders as Recommender” ( my own naming )
I had to add “import webapp.Recommenders as Recommender” where webapp is the directory I’ve stored the package in and ‘webapp’ is a subfolder of a main project folder where all my file are.