Introduction to pandas profiling in Python
 By Rituparna Mukherjee
By Rituparna MukherjeeWe know for extensive data analysis and to develop a machine learning model we use different libraries like the use of Pandas, Numpy & Matplotlib. The panda s library is mostly used in terms of building a machine learning model especially for Exploration Data Analysis for example reading the dataset, defining Dataframes, merging datasets, concatenate columns, and also zipping the two Dataframes into single Dataframe. I came across a very interesting topic named ‘pandas-profiling‘ which is extensively used for quick overall analysis report of any dataset you load & that helps to estimate your approach towards your building up the model. Let us see what it is all about-
Let’s perform a quick analysis report of any dataset we are using the ‘pandas-profiling’ library.
First, let’s learn the necessary commands for installing and uninstall pandas-profiling in the system-
- Install the library-
-
pip install python-profiling
If you are using conda use the following command-
-
conda install -conda-forge pandas_profiling
To Uninstall-
-
!pip uninstall pandas-profiling
USE IT-
- Let’s perform a quick analysis report of the dataset we are using the ‘pandas-profiling’ library. I have used movies-dataset here-
- load the libraries-
-
import pandas as pd import numpy as np
Import pandas-profiling library-
-
import pandas_profiling as pp
Import the dataset-
-
movies_df=pd.read_csv("G:\movie_dataset.csv")I have taken here a movies_dataset stored in the G folder of my system.
You can load the respective dataset you want to explore along with its file path.
movies_df.head()

This command will show the first five rows of the dataset for a quick look through the data as output.
movies_df.describe()

- This command will give a quick analysis of the dataset like the count, mean, standard deviation of the parameters the dataset contains.
- We will use the command for quick analysis-
profile=pp.ProfileReport(movies_df) profile

This command will give all the detailed analysis of your loaded dataset.
- We call pp.profilereport() which is a pandas function used to extract and generate the overall report of the dataset.
movies_df.profile_report(html='style'={'full-width'=True})
- If the profile report is not generated your notebook then you can also use this command-
profile.to_widgets()
profile.to_file(output_file="movies_profiling.html")
You will find your respective Html format report automatically saved in your default folder.
THE RESULTS OF ANALYSIS-
The pandas_profiling gives a quick and detailed analysis of each parameter present in the dataset. The profile report function gives a descriptive overview of every dimension of the data.
OVERVIEW-
The overview gives the detailed description and overview of total no of missing data, total results of warning, a total of the duplicate cells, distinct values, variables with high cardinality.

NUMERICAL OVERVIEW-
This section illustrates the properties of numerical values of the dataset to get a detailed overview of Mean, Standard deviation, Min values, Max values, Interquartile range, etc.

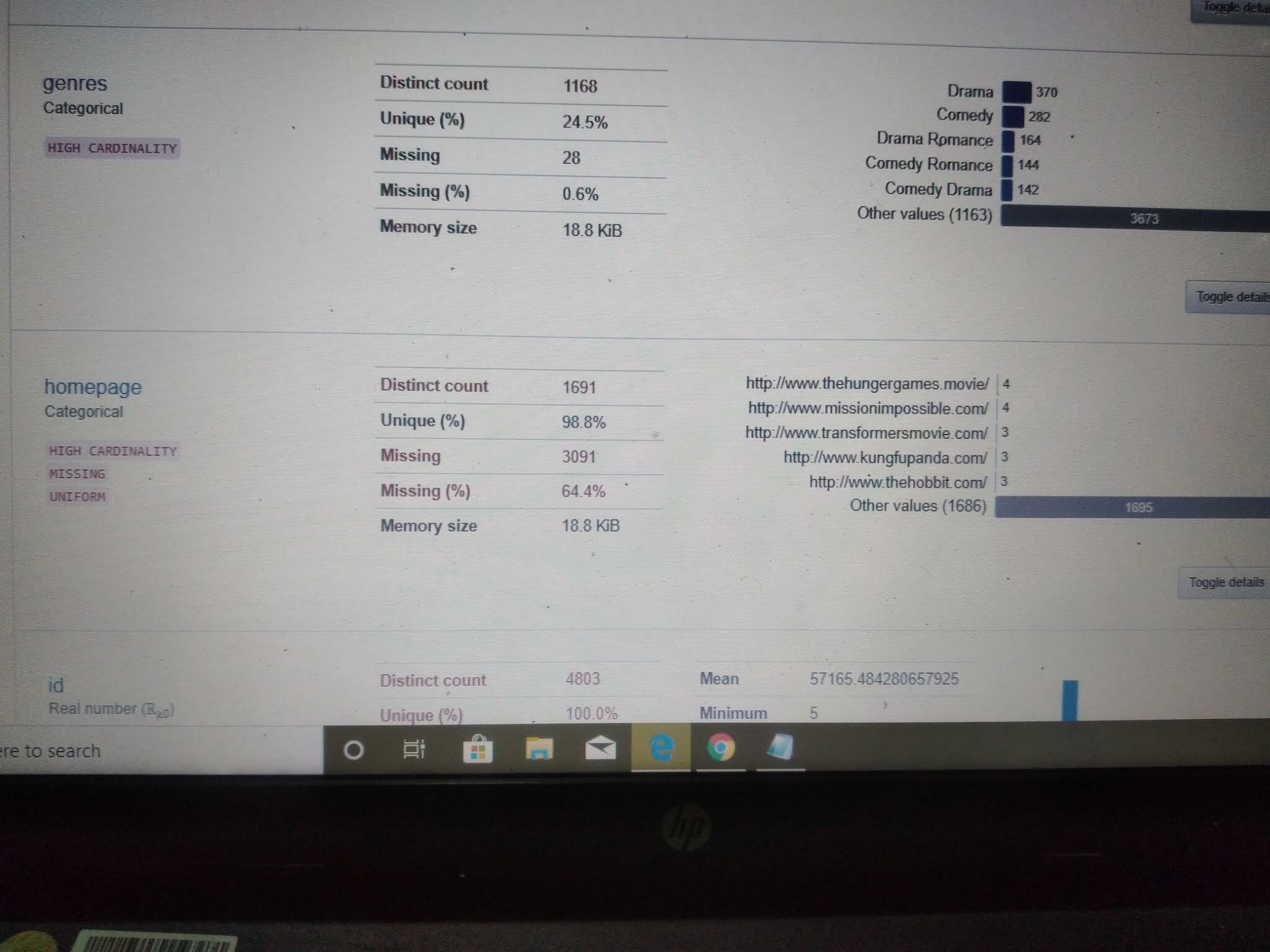
CATEGORICAL OVERVIEW-
It shows the detailed overview of results regarding variable length, No of characters, total no of unique & distinct values, common features of the categorical variables.
CORRELATION-
The correlation report justifies how the variables are strongly related. It is the statistical technique to explain the relationship the numerical and categorical features have among each other and a detailed explanation of the parameter’s relation.
Correlation analysis is the method to show the relationship between two quantitative variables present in the dataset. Correlation is defined using correlation coefficient “r” which ranges from -1 to +1. If r is negative the variables are inversely related and if r is positive then one variable has a larger value than the other.

INTERACTIONS-
In this section, you can get the generated plot that shows the interaction between the two parameters. The interaction section clearly shows how each variable is related to each other present in the dataset. Any pair o variable interaction we can see by selecting any pair of variables from the two segments or headers.

Drawbacks of using pandas-profiling-
This library is not efficient if we use to get a quick analysis of large datasets. It takes a lot of time to compute the results.
Conclusion-
I am sure you can get a brief concept of how to use the pandas-profiling library. I am hopeful that it will save much of your time on performing this kind of analytics where you can estimate your future approach rather than going into tons of computing.
Leave a Reply