How to delete Similar Images from a directory or folder in Python
 By Sarbajit De
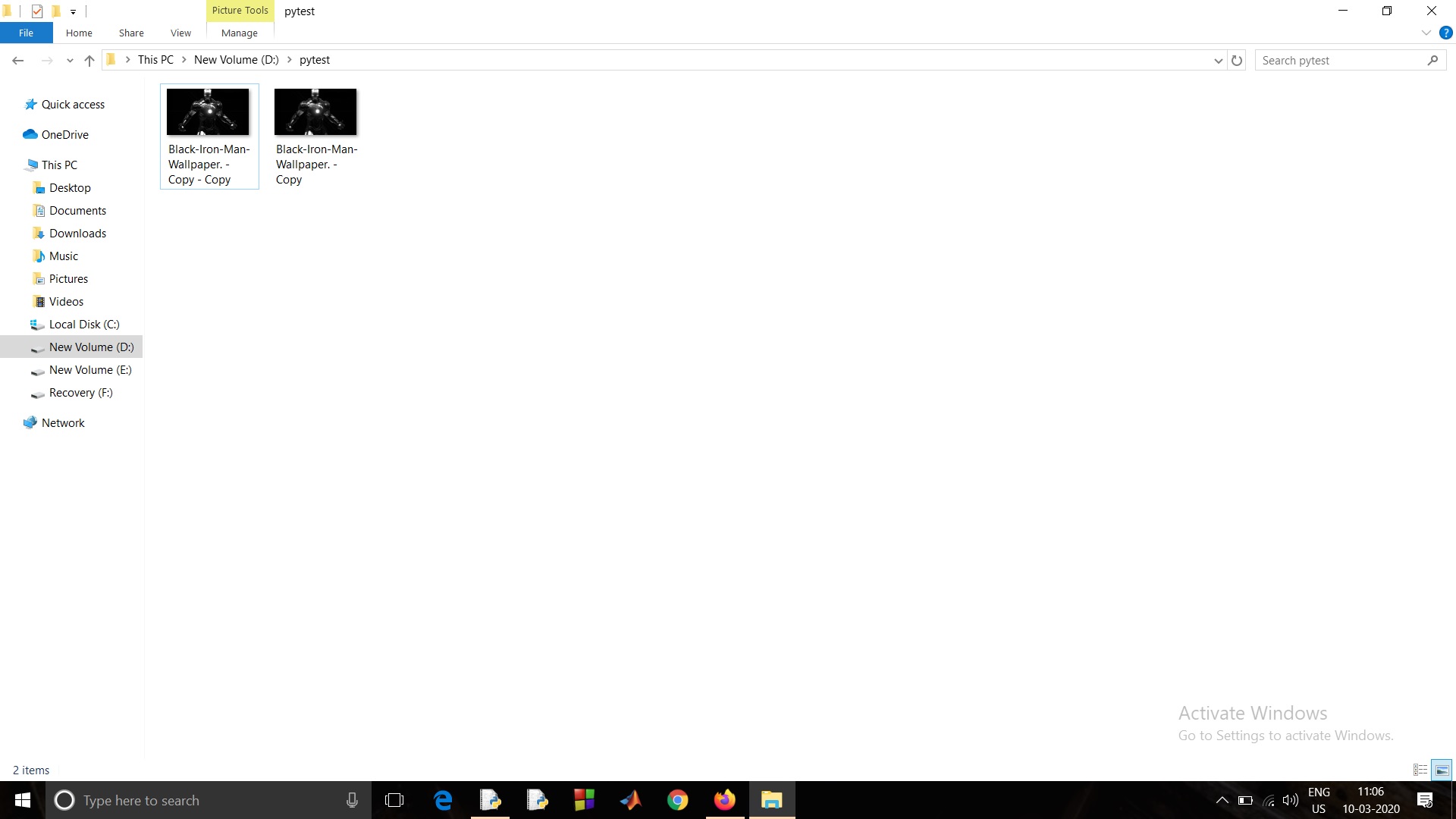
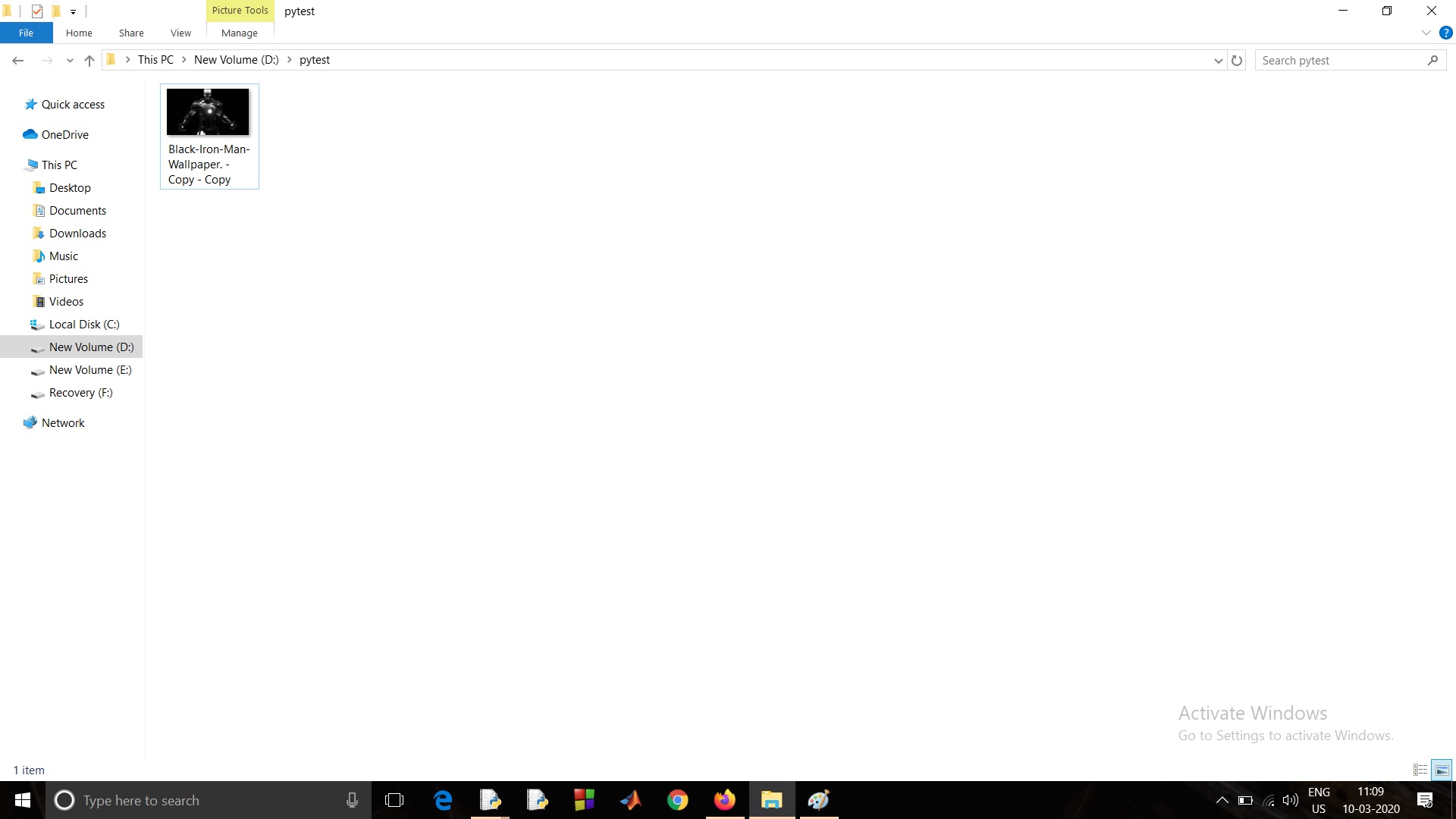
By Sarbajit DeWe all have faced this issue sometime or the other which I am going to discuss below. We have thousands of image some of which are duplicate i.e. having the same size, same image but different name. So they take up space. Now how to solve this problem of yours? These images take up your so much of your valuable space.
I have a solution to this problem of yours. Let’s see how we can. We write a Python program to delete the images which are of the same size, same image but of a different name.
Delete Similar images from a directory or folder in Python
The basic logic behind this python program is to create a hash value for each image not based on its name but based on its pixel value and count. Based on this hash value we are going to store the images in a dictionary whose key will be the hash value generated and the value will hold the binary value of the image itself.
Now based on this we store the images in a dictionary or if we find this as a duplicate we simply put this in the duplicate list having index and image binary form. Later on, we delete this list of images based on their index value.
Let’s see the code:
import hashlib
from scipy.misc import imread, imresize, imshow
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
import numpy as np
import os
def file_hash(filename):
with open(filename,'rb') as f:
return md5(f.read()).hexdigest()
os.getcwd()
os.chdir(r'D:\pytest')
os.getcwd()
files_list = os.listdir('.')
print (len(files_list))
duplicates=[]
hash_keys=dict()
for index, filename in enumerate(os.listdir('.')):
if os.path.isfile(filename):
with open(filename, 'rb') as f:
filehash = hashlib.md5(f.read()).hexdigest()
if filehash not in hash_keys:
hash_keys[filehash]=index
else:
duplicates.append((index,hash_keys[filehash]))
print(duplicates)
for file_indexes in duplicates[:30]:
try:
plt.subplot(121),plt.imshow(imread(files_list[file_indexes[1]]))
plt.title(file_indexes[1]),plt.xticks([]),plt.yticks([])
plt.subplot(122),plt.imshow(imread(files_list[file_indexes[0]]))
plt.title(str(file_indexes[0])+ 'duplicate'),plt.xticks([]),plt.yticks([])
plt.show()
except OSError as e:
continue
for index in duplicates:
os.remove(files_list[index[0]])
Let’s understand the code:
- At first, we open the directory where we are going to work. This is done by changing the current directory to chdir(ie child directory)
- We then initialize a list and a dictionary
- Then we create a hash value for each image in that folder using hashlib.md5. this creates a 32-bit hash value.
- After this, with the help of this hash value, we store it in either a dictionary or a list.
- I am plotting the same images again for your better understanding in the try block. You can skip this part if you want.
- Finally, I am removing the duplicate images using os.remove

Leave a Reply