Gradient Boosting with Scikit-learn
 By Prakhar Gupta
By Prakhar GuptaIn this post, you will get a general idea of gradient boosting machine learning algorithm and how it works with scikit-learn.
The term ‘Boosting‘ refers to a group of algorithms to create strong predictive models. By using a weak learner, it creates multiple models iteratively. Also, the final ensemble model is a combination of multiple weak models.
Gradient Boosting in machine learning
Gradient Boosting is an effective ensemble algorithm based on boosting. Above all, we use gradient boosting for regression.
Gradient Boosting is associated with 2 basic elements:
- Loss Function
- Weak Learner
- Additive Model
1. Loss Function
It is a method of evaluating how good our algorithm fits our dataset. It must be differentiable. The loss function is calculated by taking the absolute difference between our prediction and the actual value.
To learn more: Loss functions in Machine Learning
2. Weak Learner
Ordinarily, regression trees that have real values as their output for splits and whose output can be added together are used.
Decision trees are the best example of weak learner in gradient boosting.
3. Additive Model
The existing trees in the model are not changed. In addition to that trees are added one at a time. This reduces the error in every subsequent addition.
Example for Gradient Boost using sklearn in Python
Problem Statement: We are provided with a large number of PUBG game stats. Each row of the table contains one player’s post-game stats. We must build a model which can predict player’s finishing placement, on a scale from 1 (first place) to 0 (last place).
Download the required PUBG dataset for building model.
Importing required libraries and load data with pandas.
import numpy as np
import pandas as pd
from sklearn import preprocessing
from sklearn.preprocessing import LabelEncoder
import warnings
warnings.filterwarnings('ignore')
train = pd.read_csv('../DataSets/train_V2.csv')
test = pd.read_csv('../DataSets/test_V2.csv')
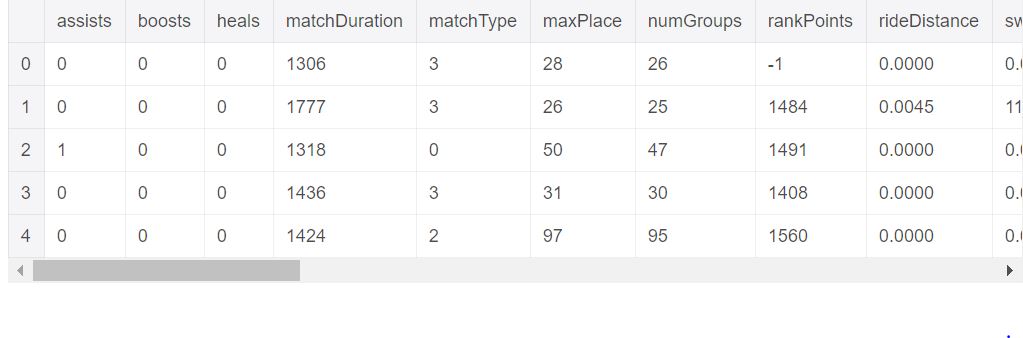
Let us now see the first 5 columns of our dataset.
train.head()

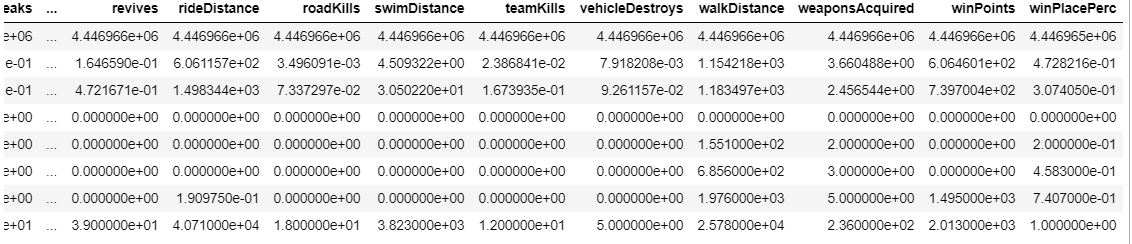
Now we check for the missing values if any.
train.describe()
#NULL value present in our target variable. We now remove extraneous row of data. train = train[train['winPlacePerc'].isna() != True]
# We create a new feature known as 'TotalDistance' which will be the combination of all sorts of distance features in our dataset. train['totalDistance'] = train['walkDistance'] + train['rideDistance'] + train['swimDistance'] test['totalDistance'] = test['walkDistance'] + test['rideDistance'] + test['swimDistance']
There are existing 16 modes of gameplay. Let us now bring it down to 4 versions of it.
- Solo
- Duo
- Squad
- Other
def standard_matchType(data):
data['matchType'][data['matchType'] == 'normal-solo'] = 'Solo'
data['matchType'][data['matchType'] == 'solo'] = 'Solo'
data['matchType'][data['matchType'] == 'solo-fpp'] = 'Solo'
data['matchType'][data['matchType'] == 'normal-solo-fpp'] = 'Solo'
data['matchType'][data['matchType'] == 'normal-duo-fpp'] = 'Duo'
data['matchType'][data['matchType'] == 'duo'] = 'Duo'
data['matchType'][data['matchType'] == 'normal-duo'] = 'Duo'
data['matchType'][data['matchType'] == 'duo-fpp'] = 'Duo'
data['matchType'][data['matchType'] == 'squad'] = 'Squad'
data['matchType'][data['matchType'] == 'squad-fpp'] = 'Squad'
data['matchType'][data['matchType'] == 'normal-squad'] = 'Squad'
data['matchType'][data['matchType'] == 'normal-squad-fpp'] = 'Squad'
data['matchType'][data['matchType'] == 'flaretpp'] = 'Other'
data['matchType'][data['matchType'] == 'flarefpp'] = 'Other'
data['matchType'][data['matchType'] == 'crashtpp'] = 'Other'
data['matchType'][data['matchType'] == 'crashfpp'] = 'Other'
return data
train = standard_matchType(train)
test = standard_matchType(test)
#Transforming the 'matchType' into categorical values with LabelEncoder() le = LabelEncoder() train['matchType']=le.fit_transform(train['matchType']) test['matchType']=le.fit_transform(test['matchType'])
#We can now check our table for matchType feature. train.head()
Model Development
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingRegressor
#Train-test split
y = train['winPlacePerc']
X = train.drop(['winPlacePerc'],axis=1)
size = 0.40
#Splitting data into training and validation set.
X_train, X_validation, Y_train, Y_validation = train_test_split(X, y, test_size=size, random_state=seed)
#Gradient Boost Regressor
GBR = GradientBoostingRegressor(learning_rate=0.8)
GBR.fit(X,y)
predictions = GBR.predict(test)
#Creating new file with result dataset. The target variable "winPlacePerc" is a number between 0 and 1.
submission = pd.DataFrame({'Id': test['Id'], 'winPlacePerc': predictions})
submission.to_csv('submission_GBR.csv',index=False)
Also read,
Leave a Reply