DataFrame, date_range(), slice() in Python Pandas library
 By Sushant Shaw
By Sushant ShawHey there everyone, in this tutorial you will learn about DataFrame along with date_range() and slice()methods in Pandas. We all know, Python is a powerful language, that allows us to use a variety of functions and libraries. It becomes a lot easier to work with datasets and analyze them due to libraries like Pandas.
So, let’s get started.
DataFrame in Pandas
DataFrame is a two-dimensional data structure used to represent tabular data. It represents data consisting of rows and columns.
For creating a Pandas DataFrame, first, we need to import the Pandas library.
import pandas as pd
Now, we will have to look at different ways of creating DataFrame. Below are given some of theme:
1. Using a ‘.csv’ file :
We can create a DataFrame by importing a ‘.csv’ file using read_csv() function, as shown in the code below:
#reading .csv file to make dataframe
df = pd.read_csv('file_location')
#displaying the dataframe
df
2. Using an excel file :
DataFrame can also be created by importing an excel file, it is similar to using a ‘.csv’ file with just a change in the function name, here you have to use the read_excel() function:
#reading the excel file to create dataframe
df = pd.read_excel('file_location')
#display dataframe
df
3. Using Dictionary:
We can also create our DataFrame using a dictionary where the key-value pairs of the dictionary will make the rows and columns for our DataFrame respectively.
#creating data using dictionary
my_data = {
'date': ['2/10/18','3/11/18','4/12/18'],
'temperature': [31,32,33],
'windspeed': [7,8,9]
}
#creating dataframe
df = pd.DataFrame(my_data)
#displaying dtaframe
df
OUTPUT:

4. Using a list of tuples :
Here, the list of tuples created would provide us with the values of rows in our DataFrame, and we have to mention the column values explicitly in the pd.DataFrame() as shown in the code below:
#creating data using tuple list
my_data = [
('1/10/18',30,6),
('2/11/18',31,7),
('3/12/18',32,7)
]
#creating dataframe
df = pd.DataFrame(data=my_data, columns= ['date','temperature','windspeed'])
#displaying dataframe
df
We can also use a list of dictionaries in place of tuples.
OUTPUT:

date_range() in Pandas
The date_range function in Pandas gives a fixed frequency DatetimeIndex.
Syntax :
pandas.date_range(start=None, end=None, periods=None, freq=None, tz=None, normalize=False, name=None, closed=None, **kwargs)
Let’s try to understand the working of some of the arguments of date_range() with the help of code and their output.
start: Left bound for generating dates.
end: Right bound for generating dates.
freq: Frequency strings can have multiple values, ex:4H
pd.date_range(start ='12-1-2019', end ='12-2-2019', freq ='4H')
OUTPUT:
DatetimeIndex(['2019-12-01 00:00:00', '2019-12-01 04:00:00',
'2019-12-01 08:00:00', '2019-12-01 12:00:00',
'2019-12-01 16:00:00', '2019-12-01 20:00:00',
'2019-12-02 00:00:00'],
dtype='datetime64[ns]', freq='4H')
periods: Number of periods to generate.
pd.date_range(start ='12-1-2019', end = '12-10-2019' , periods = 4)
OUTPUT:
DatetimeIndex(['2019-12-01', '2019-12-04', '2019-12-07', '2019-12-10'], dtype='datetime64[ns]', freq=None)
tz: Name of the Time zone for returning localized DatetimeIndex
pd.date_range(start='12/1/2019', periods=4, tz='Asia/Hong_Kong')
OUTPUT:
Also, read: Python program to Normalize a Pandas DataFrame Column
slice() in Pandas
str.slice() is used to slice a substring from a string present in the DataFrame. It has the following parameters:
start: Start position for slicing
end: End position for slicing
step: Number of characters to step
Note: “.str” must be added as a prefix before calling this function because it is a string function.
example 1:
we will try to slice the year part(“/18”) from ‘date’ present in the DataFrame ‘df’

start, stop, step = 0, -3, 1 # converting 'date' to string data type df["date"]= df["date"].astype(str) # slicing df["date"]= df["date"].str.slice(start, stop, step) df
OUTPUT:

So, we have successfully sliced the year part from the date.
example 2:
We have this DataFrame

Now, we will try to remove the decimal part from the ‘height’ present in the DataFrame ‘df’.
start, stop, step = 0, -2, 1 # converting 'height' to string data type df["height"]= df["height"].astype(str) # slicing df["height"]= df["height"].str.slice(start, stop, step) df
OUTPUT:
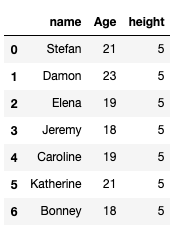
So, we have successfully removed the decimal part from ‘height’.
Leave a Reply