Classification use cases using h2o in Python and h2oFlow
 By Ayyappa Hemanth
By Ayyappa HemanthIn this article, we are going to learn about the following :
- What is h2o Framework?
- h20 vs other frameworks
- Advantages of h2o
- installation of h2o on to your local machine
- Applying machine learning models using h20 framework
- no code machine learning and deep learning with h2o Flow
Let’s Start the show……
H20 FrameWork
H2o is an opensource framework to perform predictive analytics, build machine learning models on huge data. Shockingly H2o core code was written in java but it doesn’t have a java wrapper to download and use. H2o framework is available for 3 kinds of people. first, python binding H2O-Python. second, R binding H2O-R and last the third one was for no-coding required which is web UI or H2o Flow.
Other FrameWorks available
There are many other frameworks available for performing predictive analytics, building machine learning, and building deep learning models such as the first was the most famous google’s Tensorflow, Facebook’s Pytorch, Keras, sci-kit learn and so-on. But I love Uber’s Ludwig Framework which doesn’t need coding at all!!!
Advantages of H2o FrameWork
- All famous and most useful algorithms are already available
- Can work with H20 through python, R or Web UI
- Distributed, in-memory processing
- Easy to Deploy
Installation of H20 Framework
With pip using the following command you can directly add to your environment
pip install h2o
It requires some more libraries such as requests, tabulate, Colorama e.t.c; but the above command will automatically download it for you.
classification with h2o framework
Hope many statisticians say I’m a Data Analyst but not a Data scientist, The key difference is that Data Scientist can build a model with code but a statistician might not because he was not familiar with how to code and so there is some craze for “No Code Machine Learning”. Because of that, I’m introducing a simple yet powerful tool and framework H2O-Flow. The below set of images with description shows you how to start building a predictive model from scratch just by clicking buttons.
The first step to get started is, we have to fire up the H2O-Flow web UI server. To do this we can directly run below code in your jupyter notebook

In[1] shows how to import and then you can use shift+enter to run in jupyter notebook.
In[2] shows how to initialize the server, Output will show you the local host if you go there it will show you another type of notebook like that of shown below.
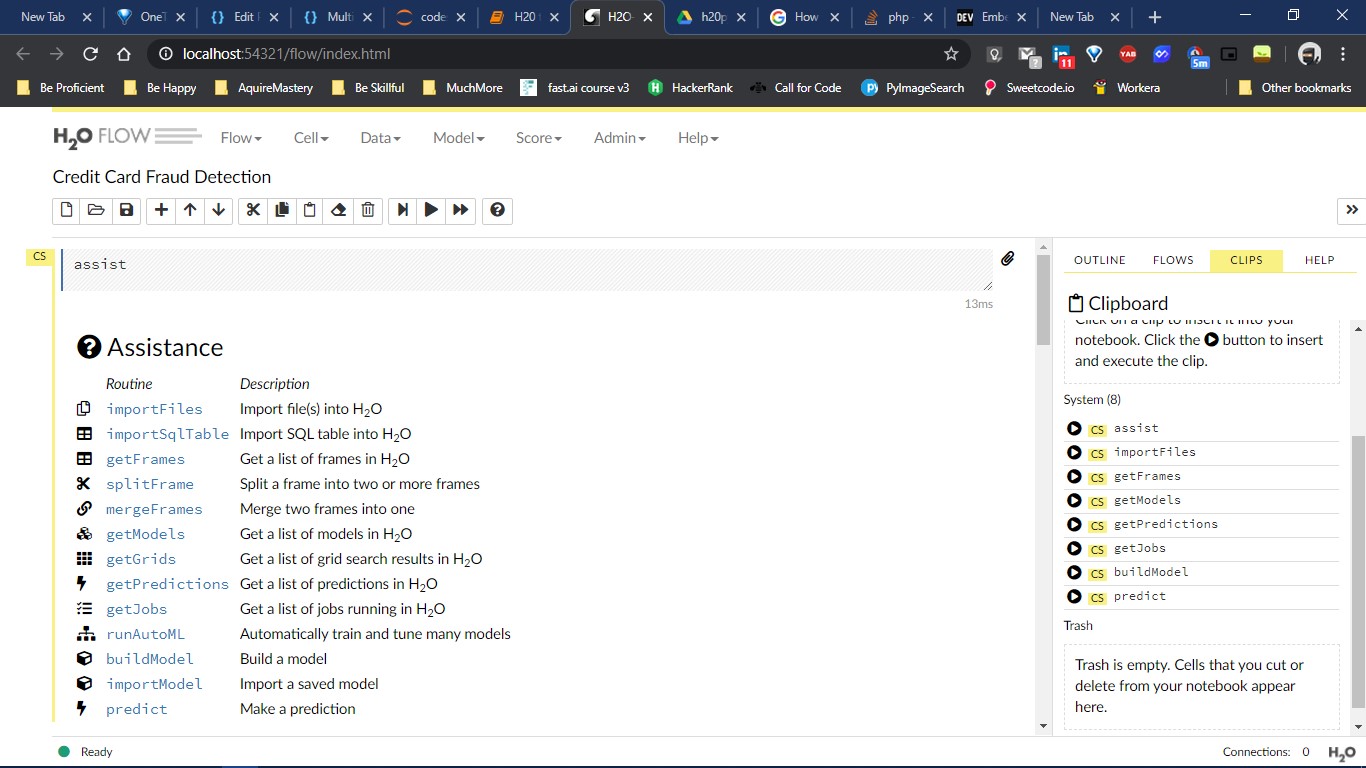
The above pictures will be there when you go to the localhost:54321. The CS in the above image means that it uses coffee-script but you need not know about it anyway
Now we are using a credit card fraud detection dataset to build our model. Now all the blue lines you can see are Clickable and when you click them it will automatically generate a new cell and writes coffee-script concerning the task. Let’s see what are the tasks to be performed.
- Import dataset into the flow
- Parse the dataset
- Split it into the training data and validation data
- Build a model
- See the performance metrics
- Advantages of this flow
When you click on the importFile in the above Assistance, it will generate the following
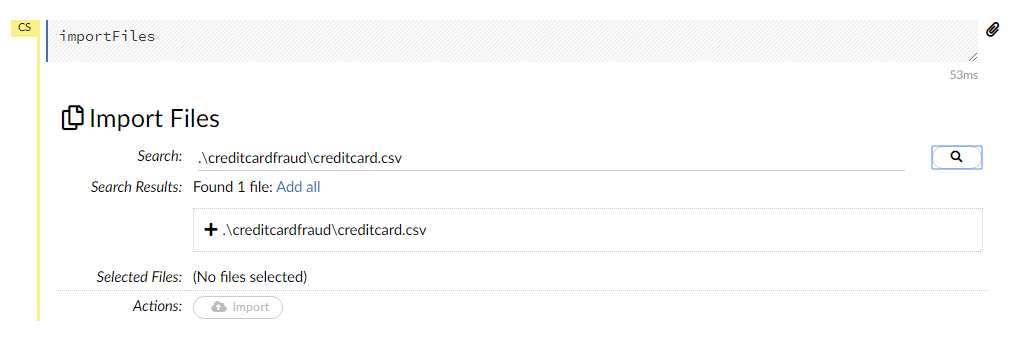
When you type the dataset file path into The above search it will show you the search results click on the search result it will add successfully and shows the import button. When you click on the import button the following cell will be generated.

Now when you click on the parse these files you will get an option to change the datatypes, imputing new values e.t.c; but I’m direct to point and my dataset doesn’t need this hence the following parsing will be shown on clicking.

You will get to click a button called parse After the data columns, on clicking following will be generated, it will show the job done and then click on the action button shown in the below picture.


Now that we have uploaded our data. All that remains is splitting and building model. Now click on the split button, it will show the below picture. Write your ratios there and click the create button it will automatically generate the second cell in the below picture.

It will show the below pic when you click On frame 0.750

On clicking build model you get the following GUI
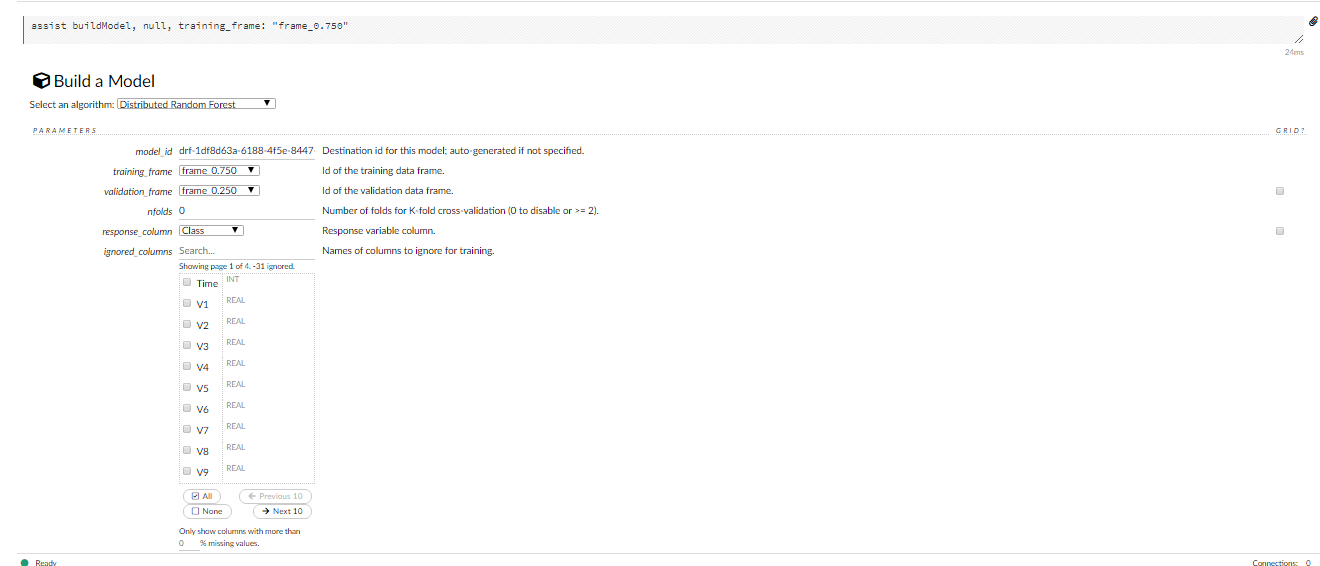
Now in the select algorithm tag, I choose Distributed Random Forest, in validation, I gave frame_0.250 and given respective column to the response_coloumn, in case you have to ignore some columns you add under ingored_columns and there are many model parameters and hyperparameters that you can give to fine-tune your model but for now, I’m leaving them to default except ntrees is 200.
Finally, it will show a pic like below
After completing the progress to a hundred you can click on actions to see the below menu

Hope from here you can help yourselves to check your metrics, parameters, and variable importances e.t.c;
Note: Please do leave a comment, feel free to share Your thoughts and doubts. I would love to learn new things by doubts from others.
Also read: Predict Next Purchase using Machine Learning in Python
Leave a Reply