Chat Bot Using NLTK in Python
 By Shrimad Mishra
By Shrimad MishraHi, guys in this post we are going to learn how to make a Chat-Bot using NLTK in Python.
In this topic, we will be coming across many new things.
First of all What is the NLTK?
NLTK is a python module that is used to make machines understand human language and reply to it with an appropriate response.
There are many inbuilt functions in the NLTK module which we are going to use to make the chatbot.
There are many modules which we are going to use in this.
import io, random, string, NumPy, warnings and many more.
Here are the modules which we are going to import
import io
import random
import string
import warnings
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import warnings
warnings.filterwarnings('ignore')
import nltk
from nltk.stem import WordNetLemmatizer
nltk.download('popular', quiet=True)
Now we are going to import a .txt file that contains the database for our Bot.
Here is the file Chatbot1.txt
From the above link download that file.
Now lets, do the remaining code
f=open('Chatbot1.txt','r',errors = 'ignore')
raw=f.read()
raw = raw.lower()
sent_tokens = nltk.sent_tokenize(raw)
word_tokens = nltk.word_tokenize(raw)
lemmer = nltk.stem.WordNetLemmatizer()
def LemTokens(tokens):
return [lemmer.lemmatize(token) for token in tokens]
remove_punct_dict = dict((ord(punct), None) for punct in string.punctuation)
def LemNormalize(text):
return LemTokens(nltk.word_tokenize(text.lower().translate(remove_punct_dict)))
GREETING_INPUTS = ("hello", "hi", "greetings", "sup", "what's up","hey",)
GREETING_RESPONSES = ["hi", "hey", "*nods*", "hi there", "hello", "I am glad! You are talking to me"]
def greeting(sentence):
for word in sentence.split():
if word.lower() in GREETING_INPUTS:
return random.choice(GREETING_RESPONSES)
def response(user_response):
robo_response=''
sent_tokens.append(user_response)
TfidfVec = TfidfVectorizer(tokenizer=LemNormalize, stop_words='english')
tfidf = TfidfVec.fit_transform(sent_tokens)
vals = cosine_similarity(tfidf[-1], tfidf)
idx=vals.argsort()[0][-2]
flat = vals.flatten()
flat.sort()
req_tfidf = flat[-2]
if(req_tfidf==0):
robo_response=robo_response+"I am sorry! I don't understand you"
return robo_response
else:
robo_response = robo_response+sent_tokens[idx]
return robo_response
flag=True
print("Shrimad's Bot: My name is Shrimad's Bot. I will answer your queries about Cricket. If you want to exit, type Bye!")
while(flag==True):
user_response = input()
user_response=user_response.lower()
if(user_response!='bye'):
if(user_response=='thanks' or user_response=='thank you' ):
flag=False
print("Shrimad's Bot: You are welcome..")
else:
if(greeting(user_response)!=None):
print("Shrimad's Bot: "+greeting(user_response))
else:
print("Shrimad's Bot: ",end="")
print(response(user_response))
sent_tokens.remove(user_response)
else:
flag=False
print("Shrimad's Bot: Bye! take care..")
Please make sure you have enough knowledge about what is tokenization if not then please go through that
and read this code.
Here is the output:-
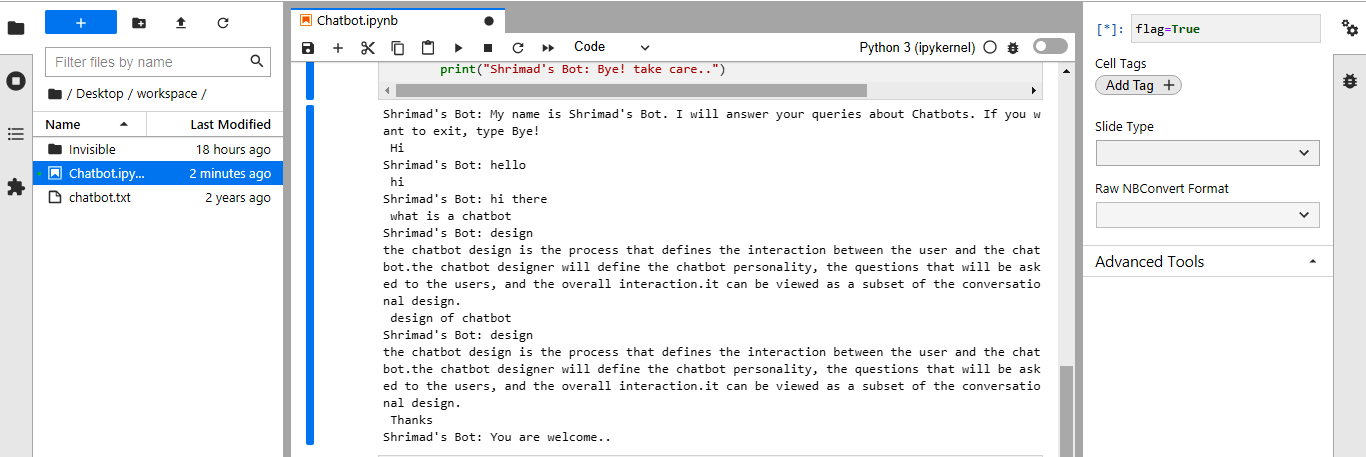
Thank You
Leave a Reply