Time Series Analysis in Python
 By Kunal Gupta
By Kunal GuptaHello everyone, In this tutorial, we’ll be discussing Time Series Analysis in Python which enables us to forecast the future of data using the past data that is collected at regular intervals of time. Then we’ll see Time Series Components, Stationarity, ARIMA Model and will do Hands-on Practice on a dataset. Let us start this tutorial with the definition of Time Series.
What is Time Series and its Application in Python
As per the name, Time series is a series or sequence of data that is collected at a regular interval of time. Then this data is analyzed for future forecasting. All the data collected is dependent on time which is also our only variable. The graph of a time series data has time at the x-axis while the concerned quantity at the y-axis. Time Series is widely used in Business, Finance and E-Commerce industries to forecast Stock market price, Future Planning strategies, Anomaly detection, etc. Let us see the Components of Time Series.
We will be working on a dataset during the whole tutorial to get a practical understanding. For this, we’ll be using a Monthly Car Sales dataset which you can check out from here.
Now we have to import some necessary Modules that we’ll be requiring.
%matplotlib inline import statsmodels as ss import numpy as np import pandas as pd import matplotlib import matplotlib.pyplot as plt from pandas.plotting import register_matplotlib_converters register_matplotlib_converters()
Don’t worry if you don’t know about the last two lines from the code. They are only used to suppress a warning that you may get while working. Now its time to read the data from the URL and apply some transformations to make it suitable to operate upon.
data = pd.read_csv(r"https://raw.githubusercontent.com/jbrownlee/Datasets/master/monthly-car-sales.csv",delimiter=",")
data['Month']=pd.to_datetime(data['Month'])
data.set_index('Month',inplace=True)
data.head()
After all these operations our data will look like this. It consists of data on Monthly sales of a car collected for 9 years and we have takes the Month Column as Index.

Time-Series Components
Time Series has basically 4 components consisting of Trend, Seasonality, Irregularity, Cyclicity.
- Trend – Trend is the overall increase or decrease or constant variation in the value of the collected data over a period of time. It can persist for a long time as well as for a short duration at least a few days. For example. On festive seasons there is an increase in sales for a product, Population growth, etc.
- Seasonality – Seasonality as the name suggests, shows a regular pattern in a quantity over an interval of time like sales of cold drinks increase in the summer every year. This is influenced by Seasonal, cultural, business factors, etc. The duration between the two cycles is short.
- Irregularity/ Residuals – It is Random Component and does not follow a specific pattern. It can consist of both Trends, Seasonality with some Random fluctuations.
- Cyclicity – Almost similar but Seasonality but the duration between two consecutive cycles is generally longer and irregular. It is not always present in data.
So these are the components of a Time Series data. For the dataset that we are using, we need to find these components in it and for that, we’ll decompose our data into all three components and Visualize it using Matplotlib Library. Let us see the code first.
from statsmodels.tsa.seasonal import seasonal_decompose decomp = seasonal_decompose(x=data, model='additive') est_trend = decomp.trend est_seasonal = decomp.seasonal est_residual = decomp.resid
fig, axes = plt.subplots(4, 1) fig.set_figheight(10) fig.set_figwidth(15) axes[0].plot(data, label='Original') axes[0].legend() axes[1].plot(est_trend, label='Trend',color="b") axes[1].legend() axes[2].plot(est_seasonal, label='Seasonality',color='r') axes[2].legend() axes[3].plot(est_residual, label='Residuals',color='g') axes[3].legend()
We have used the Additive model to decompose our data which simply means that all the components in the data are in the summation i.e Data = Trend + Seasonality + Irregularity.

Now that we have decomposed the data into the Time-Series we will see why this visualization is important when we discuss stationarity.
Concept of Stationarity in Time-Series Analysis
Stationarity refers to the system whose underlying statistical properties do not change with time, it means that time series will follow a particular behavior in the future too. It is important that the Series is stationary because working and operating upon Stationary data is much simpler.
- Mean should be constant – It conveys that there is no trend in the Time Series.
- Variance should be constant – It conveys that there is no heteroscedasticity(difference in the variance of a variable across the different intervals of time in the same data).
- Autocorrelation should be constant – To remove randomness among the data and make a constant pattern relationship.
- No Periodic component – It means that there is no seasonality.
Test to Check Stationarity
Summary Statistics
Summary statistics is basically to review the statistical properties of our data. We can divide our data into the number of small portions and then apply Statistics like mean and variance to see if they lie in a close range or differ too much. Let us convert the column Sales into an array and then will split into 9 equal parts that are 9 partitions for 9 years for our dataset and then find the mean and variance of each.
data_array = np.array(data['Sales'])
partitions = np.split(data_array, indices_or_sections=9)
print("Mean of Partitions")
np.mean(partitions, axis=1)
print("-"*20)
print("Variance of Partitions")
np.var(partitions, axis=1)


We can see that there is sufficient difference between each consecutive mean and variance values therefore we can infer that there is non-stationarity in our data. Also note that it is not compulsory that these vales should be the same, at least they should be in close range. This test does not confirm stationarity but a good method to start analyzing.
Histogram Plot
Histogram plot of the data is the next step which can confirm the statistics calculations in the summary statistics. In this method, we plot a histogram graph and if the shape or the graph closely represents a Normal distribution Curve we can confirm that data has stationarity. Let us plot a histogram plot for our data.
pd.Series(data_array).hist();
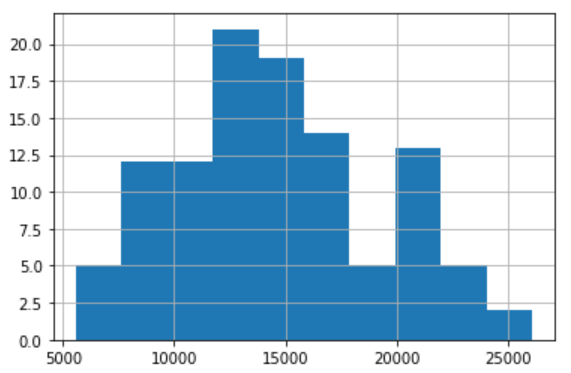
We can see that it is looking like a Normal Distribution but still has lots of differences. From here also we see that the Data is Non-Stationary.
Augmented Dickey-Fuller(ADF) Test
All the methods we have discussed are just visualization or computing standard statistics operation. ADF test is a statistical test and these types of tests can provide confirmatory evidence that your time series is stationary or non-stationary. ADF test checks for stationarity by using a hypothesis. We may wither accept or reject this hypothesis.
- Null Hypothesis – The null hypothesis is accepted and it suggests that the time series is non-stationary.
- Alternate Hypothesis: The null hypothesis is rejected and it suggests the time series is stationary.
To know whether we have to accept or reject a null hypothesis demands a threshold to be set which is set upon the p-value of the ADF Test. Generally, the threshold value is 5%.
- P-Value < 0.05 – Null hypothesis rejected and Time-Series is Stationary.
- P-Value > 0.05 – Null hypothesis accepted and Time Series is Non- Stationary.
Let us Apply the ADF statistics to our Car_Sales dataset.
from statsmodels.tsa.stattools import adfuller adf, pvalue, usedlag, nobs, critical_values, icbest = adfuller(data_array)
ADF : -1.2238127661752862
P-Value : 0.6632691049832858
Critical Values : {'1%': -3.5011373281819504, '5%': -2.8924800524857854, '10%': -2.5832749307479226}
We see that the ADF value is -1.22 it is greater than all threshold values of 0.10, 0.05, 0.01 Therefore our Time-Series data is Non-Stationary and it same result as we are getting using the Summary statistics or Histogram Plots. Being Non-Stationary simply means that data has still some time-dependent component.
You can find other parameters that we have used above from the official documentation here.
Nonstationary-to-Stationary Transformations
During tests for stationarity if we have found that our time-series is stationary then we are not required to do any transformation but if we are confirmed that our time-series is non-stationary like in the dataset we are working with we have to perform the transformations. There are numerous transformations that we can apply but we will learn some of them here.
Removing Trend & Seasonality
We have to decompose our data_array separately into Trend, Seasonal and Residual components because we may require to check their values to see that if there are null values or not as they may require to be removed. Try to print them and check the result and then we will remove them and will run the ADF test once more.
from statsmodels.tsa.seasonal import seasonal_decompose ss_decomposition = seasonal_decompose(x=data_array, model='additive',freq=12) est_trend = ss_decomposition.trend est_seasonal = ss_decomposition.seasonal est_residual = ss_decomposition.resid
print(est_trend) print(est_seasonal) print(est_residual)
Running this we have seen that there are 12 NaN values in the trend and residual components(6 in beginning and 6 in the end). We have used the frequency parameter because data_array is not a Pandas object (It is a numpy array) and also value is taken as 12 because we have a yearly data that is collected once a month. Let us remove the Residual component and run the ADF test again. This residual component adds randomness to our data so we are removing it.
new_adf, new_pvalue, usedlag_, nobs_, critical_values_, icbest_ = adfuller(est_residual[6:-6])
print("New ADF : ", new_adf)
print("Critical Values: ", critical_values_)
print("New P-value: ", new_pvalue)
New ADF : -4.523855907435011
Critical Values: {'1%': -3.5117123057187376, '5%': -2.8970475206326833, '10%': -2.5857126912469153}
New P-value: 0.00017801721326346934
From the Output above, it is interesting to note that now our data is Stationary rejecting the Null Hypothesis.
Removing Heteroscedasticity using Log Transformation
This is another method that is specifically used to remove Heteroscedasticity from our data. Just take the Log of the data and apply ADF Test to see the result. To take log use np.log(). We want you to try this and see the results. Let us move forward and model our data to make predictions.
ARIMA Model in Python
ARIMA stands for Auto-Regressive Integrated Moving Average. This model can be fitted to time series data in order to forecast or predict future data in the time- series. This model can also be used even if the time series is not stationary.
ARIMA model has 3 main parameters p, d, and q and that’s why this model can also be defined with the notation ARIMA(p, d, q). Let us see what these parameters are-
- p – It denotes the number of AutoRegressive(AR) terms in the time series.
- AutoRegression – It is a model that uses the dependent relationship between an observation and some number of lagged observations i.e the relationship between a value of a quantity collected at a time and the value of the same quantity collected at any regular interval in the past.
- d – It denotes the order of difference needed for stationarity and it is the Integrated(I) part of ARIMA. We have to get understandings of the plots and other statistics to find the right order of difference. To learn more about finding the right order of difference for your model, you can refer here.
- q – It denotes the order of Moving Average(MA) or the number of lagged forecast errors in the prediction equation.
- Moving Average(MA) – It is defined as taking averages or changing data in small portions whose size is defined as the size of the window. This window size is taken and averages are counted by moving this window one step at a time.
Implementation of ARIMA Model
from statsmodels.tsa.arima_model import ARIMA # fitting the model on the 96 values # removing the 12 NaN's values model = ARIMA(data_array[6:-6], order=(9,1,0)) model_fit = model.fit(disp=0) print(model_fit.summary()) # plot residual errors residuals = pd.DataFrame(model_fit.resid) residuals.plot() plt.show() residuals.plot(kind='kde') plt.show() print(residuals.describe())
- First, we have imported the ARIMA model from statsmodels library.
- Then we have initialized the ARIMA model using the data by removing the first and last 6 NaN values that we get in the Residual during decomposition. We also have taken the order as (9,1,0) which gives us the least values of AIC and BIC values that are considered to be as low as possible to make a good model.
- The next step is to fit the model and then we have printed a summary of the model.
- Now it is important to focus on the residual part of the data to make good predictions and for that, we have plot several plots and describe the residual part after fitting.
ARIMA Model Results
==============================================================================
Dep. Variable: D.y No. Observations: 95
Model: ARIMA(9, 1, 0) Log Likelihood -865.796
Method: css-mle S.D. of innovations 2139.147
Date: Sun, 24 Nov 2019 AIC 1753.593
Time: 19:48:50 BIC 1781.685
Sample: 1 HQIC 1764.944
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
const 90.6426 61.383 1.477 0.143 -29.665 210.950
ar.L1.D.y -0.2018 0.090 -2.251 0.027 -0.378 -0.026
ar.L2.D.y -0.1032 0.081 -1.269 0.208 -0.263 0.056
ar.L3.D.y -0.4177 0.081 -5.158 0.000 -0.576 -0.259
ar.L4.D.y -0.4767 0.088 -5.387 0.000 -0.650 -0.303
ar.L5.D.y -0.2567 0.097 -2.650 0.010 -0.447 -0.067
ar.L6.D.y -0.2608 0.087 -2.992 0.004 -0.432 -0.090
ar.L7.D.y -0.1224 0.080 -1.532 0.129 -0.279 0.034
ar.L8.D.y -0.4455 0.079 -5.634 0.000 -0.600 -0.291
ar.L9.D.y -0.4543 0.090 -5.051 0.000 -0.631 -0.278
Roots
=============================================================================
Real Imaginary Modulus Frequency
-----------------------------------------------------------------------------
AR.1 0.8927 -0.5278j 1.0370 -0.0850
AR.2 0.8927 +0.5278j 1.0370 0.0850
AR.3 0.4907 -0.8979j 1.0232 -0.1704
AR.4 0.4907 +0.8979j 1.0232 0.1704
AR.5 -0.3033 -1.0804j 1.1221 -0.2936
AR.6 -0.3033 +1.0804j 1.1221 0.2936
AR.7 -0.9354 -0.5896j 1.1057 -0.4105
AR.8 -0.9354 +0.5896j 1.1057 0.4105
AR.9 -1.2698 -0.0000j 1.2698 -0.5000
-----------------------------------------------------------------------------
count 95.000000 mean 4.727658 std 2174.702813 min -4284.663699 25% -1325.167207 50% -80.893961 75% 1357.012284 max 6008.075329

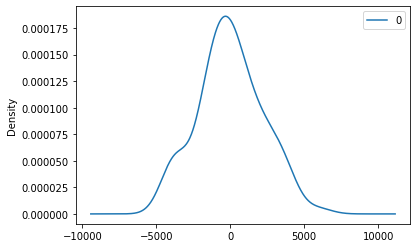
Note
- We can change the order to make a more accurate model. Try to change them
- To make forecasts just split the data into training and testing sets, then fit data the model using training data and then make forecast() method on the test data and just compare the test data with the predicted data. This is simple and is basically like any machine learning model.
We hope you like this tutorial and if you have any doubts, feel free to leave a comment below.
You may like to read
Leave a Reply