Stacking Ensemble Machine Learning in Python
 By Sumit Singh
By Sumit SinghIn this tutorial, we will learn about the Stacking ensemble machine learning algorithm in Python. It is a machine learning algorithm that combines predictions of machine learning models, like bagging and boosting.
It involves two base models level-0 and level-1 models. The other is commonly known as the meta-model or level-1. This model is used in predicting the base model.
- Level-0 Models: Fitting of the model done after training the model on the data.
- Level-1 Models: We use this model to learn and then combine the forecast made by the level-0 model.
Output received from the level-0 model is used in the training level-1 model.
Stacking for Classification & Regression in Python
1. Classification
The make_classification() function can prove to be helpful here as this will create a binary classification problem.
from sklearn.datasets import make_classification X, Y = make_classification(n_samples=1500, n_features=30, n_informative=20, n_redundant=5, random_state=1)
Next, predicting models using various algorithms. Algorithms are:
- Support Vector Machine.
- k-Nearest Neighbors.
- Decision Tree.
- Logistic Regression.
- Naive Bayes.
def new_models(): models = dict() models['lr'] = LogisticRegression() models['knn'] = KNeighborsClassifier() models['cart'] = DecisionTreeClassifier() models['svm'] = SVC() models['bayes'] = GaussianNB() models['stacking'] = new_stacking() return models
Next, combining models into one mode with the help of stacking. Now, combining predictions of the five models using logistic regression.
def new_stacking():
level0 = list()
level0.append(('lr', LogisticRegression()))
level0.append(('knn', KNeighborsClassifier()))
level0.append(('cart', DecisionTreeClassifier()))
level0.append(('svm', SVC()))
level0.append(('bayes', GaussianNB()))
level1 = LogisticRegression()
model = StackingClassifier(estimators=level0, final_estimator=level1, cv=5)
return model
Using evaluate_model() function to obtain list of scores.
def eval_model(model): cv = RepeatedStratifiedKFold(n_splits=20, n_repeats=4, random_state=2) scr = cross_val_score(model, X, Y, scoring='accuracy', cv=cv, n_jobs=-2, error_score='raise') return scr
Driver code.
X, Y = new_dataset()
models = new_models()
results, names = list(), list()
for name, model in models.items():
scr = eval_model(model)
results.append(scores)
names.append(name)
print('>%s %.4f (%.4f)' % (name, mean(scr), std(scr)))
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()
Output:
>lr 0.8353 (0.0383) >knn 0.9307 (0.0297) >cart 0.7583 (0.0430) >svm 0.9435 (0.0306) >bayes 0.7950 (0.0441) >stacking 0.9583 (0.0240)

2. Regression:
The make_regression() function can be helpful here as this will create a regression problem.
from sklearn.datasets import make_regression X, Y = make_regression(n_samples=1500, n_features=30, n_informative=20, noise=0.1, random_state=1)
Next, predicting models using various algorithms. Algorithms are:
- Support Vector Regression.
- Decision Tree.
- k-Nearest Neighbors.
Create a model you wish to evaluate using the new_models() function.
def new_models(): models = dict() models['knn'] = KNeighborsRegressor() models['cart'] = DecisionTreeRegressor() models['svm'] = SVR() models['stacking'] = new_stacking() return models
Next, combining models into one mode with the help of stacking. Now, combining predictions from each of the separate three models using linear regression.
def new_stacking():
level0 = list()
level0.append(('knn', KNeighborsRegressor()))
level0.append(('cart', DecisionTreeRegressor()))
level0.append(('svm', SVR()))
level1 = LinearRegression()
model = StackingRegressor(estimators=level0, final_estimator=level1, cv=5)
return model
Using evaluate_model() function obtain a list of scores.
def eval_model(model): cv = RepeatedKFold(n_splits=20, n_repeats=4, random_state=2) scr = cross_val_score(model, X, Y, scoring='neg_mean_absolute_error', cv=cv, n_jobs=-2, error_score='raise') return scr
The mean absolute error (MAE) can be used here. The scikit-learn library maximizes, from -infinity to 0 for the best score to invert the sign of an error.
Driver code.
X, Y = new_dataset()
models = new_models()
results, names = list(), list()
for name, model in models.items():
scr = evaluate_model(model)
results.append(scr)
names.append(name)
print('>%s %.4f (%.4f)' % (name, mean(scr), std(scr)))
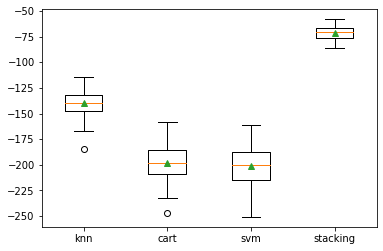
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()
Output:
>knn -140.1542 (12.8824) >cart -198.4270 (17.8205) >svm -200.7247 (18.1583) >stacking -71.0506 (6.6014)
Hope you had fun learning with me. Have a good day and happy learning.
Leave a Reply