Solving Linear Regression without using Sklearn and TensorFlow
 By Tuhin Mitra
By Tuhin MitraIn this post, I’ll be writing about ways by which you can actually make a prediction on training data sets using Linear Regression Algorithm, that too by doing all maths by yourself. And my main motif in this tutorial will be to understand how the mathematics behind the Machine Learning models can be useful to do amazing jobs.
So I have created my custom data set (Study hours vs Marks obtained) randomly, and I have plotted the graph using matplotlib. And it looks like this:

From this data set, it seems pretty hard to predict the relation between, “marks obtained by a student” and “number of hours he did study per day”.
But still, we will try to find the best fit straight line with the maximum accuracy using Linear Regression Algorithm.
Now, we know that any straight line is of the form, y=mx + c. Where m is the change in y divided by change in x.
If we use that to predict the relation between “study hours” and “marks”, the graph will look like this:
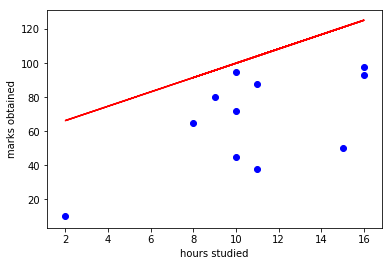
which seems to be pretty inaccurate even in our bare eyes!
To get a better result we can use “Least Square Regression”.
And the formula for that is:

I have used the following script to calculate the relation between hours and marks based on this formula:
import numpy as np
hrs_arr = np.array(hours_data)
hrs_mean = np.mean(hrs_arr)
marks_arr = np.array(marks_data)
marks_mean = np.mean(marks_arr)
numerator =[]
for index,x_elem in enumerate(hrs_arr):
numerator.append((x_elem - hrs_mean)*(marks_arr[index] - marks_mean))
print('Numerator:',sum(numerator))
denomenator = []
for x_elem in hrs_arr:
denomenator.append((x_elem - hrs_mean)**2)
print('Denomenator:',sum(denomenator))
slope = sum(numerator)/sum(denomenator)
print(f'Slope = {slope:.02f}')
y_interceptbias = marks_mean - slope*hrs_mean
print(y_interceptbias)
print(f'Best fit Linear Equation:\ny={slope:.02f} * x + {y_interceptbias:.02f}')
After you get the slope and the y-intercept bias, then you can plot and compare your results against the training data sets. simply, write this script for the calculation:
predicted_new = []
for x in hours_data:
predict = slope*x + y_interceptbias
predicted_new.append(predict)
plt.plot(hours_data, predicted_new, color = 'g')
plt.scatter(hours_data, marks_data, color = 'r')
plt.xlabel('Hours Studied')
plt.ylabel('Marks Obtained')
Now the graph obtained seems pretty much generalized to the test data sets!
Try running the code with some test dataset values to see the marks prediction.
And the graph generated will be a straight line and looks somewhat like this:
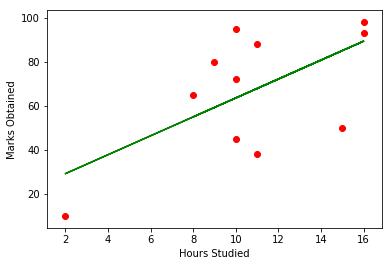
Leave a Reply