Random forest for regression and its implementation
 By Deepshi Sharma
By Deepshi SharmaIn this tutorial, as said before, I would be discussing the implementation of random forest algorithm for regression problem in Python. In my previous tutorial, I presented you how to implement random forest algorithm for classification in Python. Regression is applied to the problems where we have to predict things. For example, stock prices prediction, prediction of salary at any specified point, etc. There are many other algorithms like simple linear regression, multiple regression, polynomial regression, support vector regression, etc.
NOTE:-
Although there are many open source libraries to implement it, here is the simplest one I guess. First of all make sure , you have installed all the libraries that I am mentioning here.
Modules required to implement Random Forest Algorithm for Regression
- numpy
- matplotlib
- pandas
- sklearn
- randomForestClassifier
Here is the link to data set I have used – Position_Salaries.CSV
You can download this file.
Problem Statement:
We have been given salaries corresponding to specific positions. We have to predict the salary for a specific position that I have mentioned in next section.
Random forest for regression and its implementation in Python
If you want to learn this algorithm, read it: Introduction to Random Forest algorithm
Here I present the step by step guide to implement the algorithm in python.
- After you have imported all the libraries, import the data set.
dataset = pd.read_csv('Position_Salaries.csv')
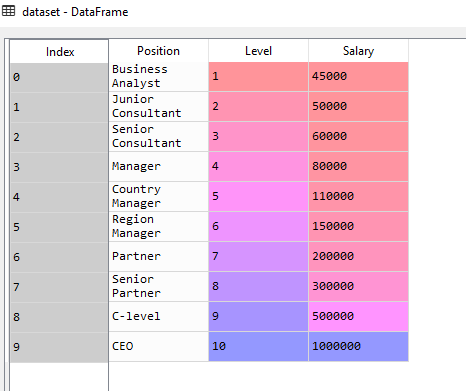
- Use only relevant columns in the data set as unnecessary columns (rather I should say features) decrease the accuracy of the model. “.iloc” to take columns mentioned in the square brackets and “.values” to take values present in the columns.
X = dataset.iloc[:, 1:2].values
y = dataset.iloc[:, 2].values


- Next step is to split the data set into training and testing data set. Training set is the set on which model is trained. Testing set is set on which model is tested i.e. results are predicted. As I have taken only 10 entries, i have skipped splitting of data set.
- Go through your data set. If you see your data set has different attributes with considerable difference in their range, go for feature scaling otherwise not. For example in data set I have used, I have skipped feature scaling because all features have approx. same range.
- Next step is an important one i.e fitting the model. As the data set I am using is quite simple, you can use little complex data set and tune the parameters accordingly.
from sklearn.ensemble import RandomForestRegressor regressor = RandomForestRegressor(n_estimators = 10, random_state = 0) regressor.fit(X, y)
- Now after training, you can predict the results. Here, for instance, I have predicted the salary for level 6.5 which lie somewhere between “Region manager” and “Partner” position if I talk in literal terms.
y_pred = regressor.predict(6.5)
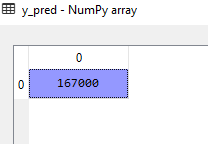
Predicted
- Next step is to visualize the predicted results.
X_grid = np.arange(min(X), max(X), 0.01)
X_grid = X_grid.reshape((len(X_grid), 1))
plt.scatter(X, y, color = 'red')
plt.plot(X_grid, regressor.predict(X_grid), color = 'blue')
plt.title('Truth or Bluff (Random Forest Regression)')
plt.xlabel('Position level')
plt.ylabel('Salary')
plt.show()
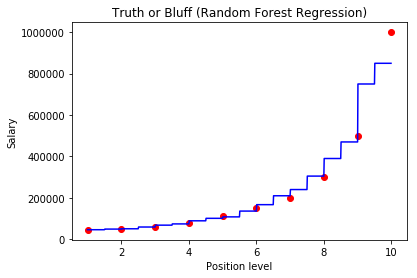
Hope this tutorial will help you in understanding the random forest algorithm for regression. You can modify this code and add more complex things that describe your problem.
You can always post your doubts in the comment section.
Also, give a read to Introduction to Random Forest algorithm
Leave a Reply