How to prevent our model from overfitting in neural networks
 By Sumit Chhirush
By Sumit ChhirushHello programmers, in this tutorial we will learn how to prevent our model from overfitting in neural networks with the help of Python programming.
We can prevent our model by adding a “Dropout” layer in between the layers.
Let’s see how we can add dropout in our layers.
So for today’s model, we have the Rock-Paper-Scissors dataset, a dataset in which we have images of hand images in Rock, Paper, and Scissors poses.
All the codes are done in a collab notebook
Download and Prepare the Dataset
# Download the train set
!wget https://storage.googleapis.com/tensorflow-1-public/course2/week4/rps.zip
# Download the test set
!wget https://storage.googleapis.com/tensorflow-1-public/course2/week4/rps-test-set.zip
- Now we have to extract the archive from the zip file.
import zipfile
# Extract the archive
local_zip = './rps.zip'
zip_ref = zipfile.ZipFile(local_zip, 'r')
zip_ref.extractall('tmp/rps-train')
zip_ref.close()
local_zip = './rps-test-set.zip'
zip_ref = zipfile.ZipFile(local_zip, 'r')
zip_ref.extractall('tmp/rps-test')
zip_ref.close()
- Now we have to assign the directory names
import os base_dir = 'tmp/rps-train/rps' rock_dir = os.path.join(base_dir, 'rock') paper_dir = os.path.join(base_dir, 'paper') scissors_dir = os.path.join(base_dir, 'scissors')
Prepare the ImageDataGenerator
Now we have to prepare ImageDataGenerator and have to pass the proper path to training and validation example.
From the Python code given below, we can do that easily.
from keras_preprocessing.image import ImageDataGenerator
TRAINING_DIR = "tmp/rps-train/rps"
training_datagen = ImageDataGenerator(
rescale = 1./255)
VALIDATION_DIR = "tmp/rps-test/rps-test-set"
validation_datagen = ImageDataGenerator(rescale = 1./255)
train_generator = training_datagen.flow_from_directory(
TRAINING_DIR,
target_size=(150,150),
class_mode='categorical',
batch_size=126
)
validation_generator = validation_datagen.flow_from_directory(
VALIDATION_DIR,
target_size=(150,150),
class_mode='categorical',
batch_size=126
)
Build the model
So now in the model building, we are going to use the “Dropout” layer
We are building a CNN model and we are using convolution layers with 64-64and 128-128 filters along with the “relu” activation function then we have to append the “Dropout” layer to avoid overfitting in our model.
Now we use a dense layer for classification and at last dense layer with softmax activation function for 3 neurons.
import tensorflow as tf
model = tf.keras.models.Sequential([
# This is the first convolution
tf.keras.layers.Conv2D(64, (3,3), activation='relu', input_shape=(150, 150, 3)),
tf.keras.layers.MaxPooling2D(2, 2),
# The second convolution
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
# The third convolution
tf.keras.layers.Conv2D(128, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
# The fourth convolution
tf.keras.layers.Conv2D(128, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
# Flatten the results to feed into a DNN
tf.keras.layers.Flatten(),
tf.keras.layers.Dropout(0.5), #Here we use Droupot to prevent our model from overfitting
# 512 neuron hidden layer
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(3, activation='softmax')
])
Now we have to compile our model for this we are using the “categorical_crossentropy” loss function and “rmsprop” as an optimizer.
model.compile(loss = 'categorical_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
Train the model
Now we are going to train our model with 25 epochs and 20 step_per_epoch and then we will see a graph of training and validation accuracy.
# Train the model history = model.fit(train_generator, epochs=25, steps_per_epoch=20, validation_data = validation_generator, verbose = 1, validation_steps=3)
output: Epoch 1/25 20/20 [==============================] - 35s 1s/step - loss: 1.1972 - accuracy: 0.3643 - val_loss: 1.0944 - val_accuracy: 0.4919 Epoch 2/25 20/20 [==============================] - 21s 1s/step - loss: 1.0978 - accuracy: 0.3687 - val_loss: 0.9753 - val_accuracy: 0.5968 Epoch 3/25 20/20 [==============================] - 21s 1s/step - loss: 1.0966 - accuracy: 0.4675 - val_loss: 0.9763 - val_accuracy: 0.5027 Epoch 4/25 20/20 [==============================] - 21s 1s/step - loss: 0.8772 - accuracy: 0.5821 - val_loss: 0.3818 - val_accuracy: 0.9435 Epoch 5/25 20/20 [==============================] - 21s 1s/step - loss: 0.8043 - accuracy: 0.6357 - val_loss: 0.5823 - val_accuracy: 0.7258 Epoch 6/25 20/20 [==============================] - 21s 1s/step - loss: 0.7805 - accuracy: 0.6607 - val_loss: 0.3778 - val_accuracy: 0.9462 Epoch 7/25 20/20 [==============================] - 22s 1s/step - loss: 0.6079 - accuracy: 0.7631 - val_loss: 0.1536 - val_accuracy: 0.9839 Epoch 8/25 20/20 [==============================] - 21s 1s/step - loss: 0.4512 - accuracy: 0.8190 - val_loss: 0.1213 - val_accuracy: 0.9919 Epoch 9/25 20/20 [==============================] - 21s 1s/step - loss: 0.5027 - accuracy: 0.7996 - val_loss: 0.4547 - val_accuracy: 0.7661 Epoch 10/25 20/20 [==============================] - 21s 1s/step - loss: 0.3014 - accuracy: 0.8782 - val_loss: 0.4801 - val_accuracy: 0.7796 Epoch 11/25 20/20 [==============================] - 21s 1s/step - loss: 0.4572 - accuracy: 0.8329 - val_loss: 0.1853 - val_accuracy: 0.9677 Epoch 12/25 20/20 [==============================] - 21s 1s/step - loss: 0.2298 - accuracy: 0.9218 - val_loss: 0.0423 - val_accuracy: 1.0000 Epoch 13/25 20/20 [==============================] - 22s 1s/step - loss: 0.3249 - accuracy: 0.8825 - val_loss: 0.0651 - val_accuracy: 0.9651 Epoch 14/25 20/20 [==============================] - 21s 1s/step - loss: 0.2401 - accuracy: 0.9115 - val_loss: 0.0483 - val_accuracy: 0.9839 Epoch 15/25 20/20 [==============================] - 21s 1s/step - loss: 0.1303 - accuracy: 0.9540 - val_loss: 0.0315 - val_accuracy: 1.0000 Epoch 16/25 20/20 [==============================] - 21s 1s/step - loss: 0.1644 - accuracy: 0.9393 - val_loss: 0.1398 - val_accuracy: 0.9570 Epoch 17/25 20/20 [==============================] - 21s 1s/step - loss: 0.1700 - accuracy: 0.9329 - val_loss: 0.0824 - val_accuracy: 0.9597 Epoch 18/25 20/20 [==============================] - 21s 1s/step - loss: 0.1799 - accuracy: 0.9405 - val_loss: 0.0265 - val_accuracy: 1.0000 Epoch 19/25 20/20 [==============================] - 21s 1s/step - loss: 0.1203 - accuracy: 0.9552 - val_loss: 0.0587 - val_accuracy: 0.9677 Epoch 20/25 20/20 [==============================] - 22s 1s/step - loss: 0.1242 - accuracy: 0.9548 - val_loss: 0.0212 - val_accuracy: 1.0000 Epoch 21/25 20/20 [==============================] - 22s 1s/step - loss: 0.1606 - accuracy: 0.9429 - val_loss: 0.0833 - val_accuracy: 1.0000 Epoch 22/25 20/20 [==============================] - 22s 1s/step - loss: 0.0861 - accuracy: 0.9758 - val_loss: 0.0217 - val_accuracy: 1.0000 Epoch 23/25 20/20 [==============================] - 21s 1s/step - loss: 0.1467 - accuracy: 0.9532 - val_loss: 0.0491 - val_accuracy: 0.9785 Epoch 24/25 20/20 [==============================] - 22s 1s/step - loss: 0.1278 - accuracy: 0.9532 - val_loss: 0.0215 - val_accuracy: 0.9973 Epoch 25/25 20/20 [==============================] - 21s 1s/step - loss: 0.0725 - accuracy: 0.9798 - val_loss: 0.0696 - val_accuracy: 0.9839
Graph of training and validation accuracy.
import matplotlib.pyplot as plt
# Plot the results
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'r', label='Training accuracy')
plt.plot(epochs, val_acc, 'b', label='Validation accuracy')
plt.title('Training and validation accuracy')
plt.legend(loc=0)
plt.figure()
plt.show()
output:
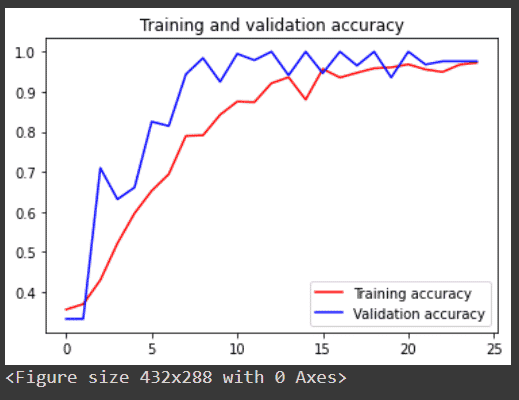
Now comment on the code line where we use the dropout layer and then run the whole program again and you will observe that after using the dropout layer our model fits better and have higher accuracy and also less zig-zag.
Below I share the graph of training and validation accuracy without the dropout layer.
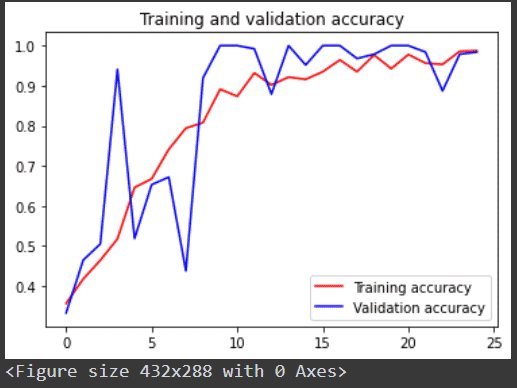
Thus, we have learned how to prevent our model from overfitting in neural networks using the dropout layer.
Leave a Reply