Natural Language Processing and its implementation in Python
 By Deepshi Sharma
By Deepshi SharmaIn the previous tutorial on Natural Language Processing, I have discussed the basic introduction and intuition behind NLP. In this tutorial, I am going to discuss the implementation of Natural Language Processing on basic problem in python.
Problem Statement:
There is a file (.tsv format file) which contains thousands of reviews for a restaurant. We have to classify the review is good or bad according to words present in the review.
This is the link to file that I have used Restaurant_Reviews.tsv.
Natural Language Processing and its implementation :
So, this is a step by step guide to basic application of NLP i.e. text processing in python.
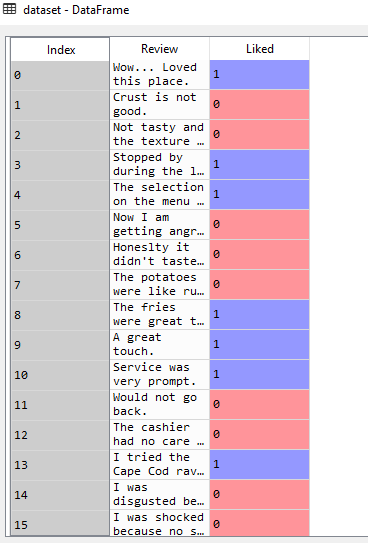
- First, import the data set on which we have to apply the text processing. Now since I have a .tsv file, I have taken delimiter as “\t”.
data = pd.read_csv('Restaurant_Reviews.tsv', quoting = 3, delimiter = '\t')
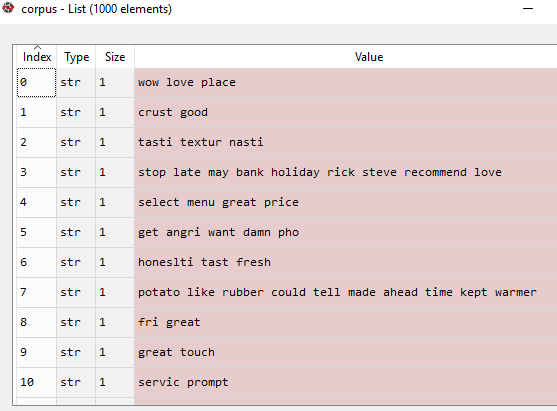
- Next step is to clean the data set that we have taken. Data cleaning involves removing stopwords, stemming, etc. First of all, I have imported all the necessary libraries. Next, we make an array corpus. Then a loop for a thousand reviews is there. Under this for loop, sentence is broken into words. Then for each word in review, we will check if it is stopword or not. For the former case, we will append the word in the review. Basically what we are doing is removing stop words from the review. These words are then put into corpus array.
import re
import nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
from nltk.stem.porter import PorterStemmer
corpus = []
for i in range(0, 1000):
reviews = re.sub('[^a-zA-Z]', ' ', data['Review'][i])
reviews = review.lower()
reviews = review.split()
porter = PorterStemmer()
review = [porter.stem(word) for word in reviews if not word in set(stopwords.words('english'))]
reviews = ' '.join(reviews)
corpus.append(reviews)
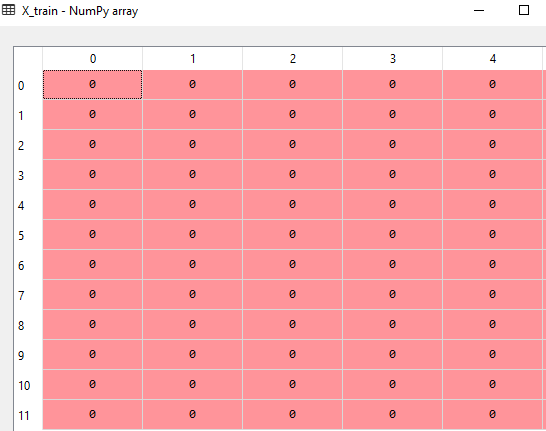
- Next step is creating a bag of words model. This model basically consists of all unique words present in reviews. This is our complete data set after the preprocessing step.
from sklearn.feature_extraction.text import CountVectorizer
cv = CountVectorizer(max_features = 1500)
X = cv.fit_transform(corpus).toarray()
y = data.iloc[:, 1].values
- Next, we have to split our data set into training and testing sets.
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.20, random_state = 0)

- Apply algorithm of your choice to fit the model. For the sake of example, I took naive bayes algorithm to fit the model.
-
from sklearn.naive_bayes import GaussianNB classifier = GaussianNB() classifier.fit(X_train, y_train)
- Next step is applying the model to the testing set to predict the results.
y_pred = classifier.predict(X_test)

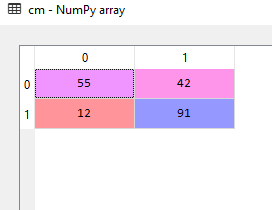
- Next step is to evaluate the performance of your model i.e. examining how much is it predicting accurately and how much wrong.
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
Here, I would like to end this tutorial. If you have any doubts, feel free to post your doubts in the comments section.
If you are not clear with this code, read the intuition behind NLP which is here Introduction to Natural Language Processing- NLP
Also, give a read to Understanding Support vector machine(SVM)
Leave a Reply