Lasso, Ridge and Elastic Net Regularization in Python
 By Premkumar Vemula
By Premkumar VemulaIn this tutorial, we will explore the different types of regularization, their advantages and disadvantages and how to apply them and implement the same in Python.
When the number of training samples(n) is far greater than the number of predictors(m) then the variance our training model is less. Thus the model will perform well on unseen test data. If the number of training samples(n) is less than the number of predictors(m) then there exists no unique solution. If ‘n’ is greater than ‘m’ but close to it then there is a high chance that variance of our model is high. In this case we have two options either increase ‘n’ or decrease ‘m’. Increasing number of data points is not easy, it means we need to design and perform new experiments which will add up to a huge amount cost and corresponding time as well. Now to decrease number of predictors(m) we have different method namely, Subset Selection, Shrinkage, Dimensionality Reduction. Of these Shrinkage is done by using regularization.
Let’s dive into each type of regularization..
Ridge Regression in Python
We all know that Residual sum of square(RSS) of error is given by

Ridge Regression is an addition of l2 norm to this equation which now looks like
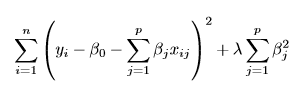
where lambda is hyperparameter which needed to be tuned. When lambda value is zero Ridge Regression resembles RSS and all the parameters shrink to zero when lambda is infinite. In between, there is an optimum value for lambda where we have least MSE and where variance and bias and optimum.
Let us try to visualize this with the help of actual data
Import Data
import pandas as pd
sheet=pd.read_csv('E:/Engineering/Mtech/Sem3/Datamining/Excercises/regularization_30_points.csv')
sheetx = sheet[['x','x.1','x.2','x.3','x.4','x.5','x.6','x.7','x.8','x.9']]
sheety=sheet[['y']]
sheet.head()
Output:

As you can see there are 10 predictors in our data. We then stored all the predictors in ‘sheetx’ and responses in ‘sheety’.
Fit the RSS model
from sklearn.linear_model import LinearRegression reg=LinearRegression() reg.fit(sheetx,sheety)
Output :
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None, normalize=False)
This output indicates the default settings of LinearRegression class
print(reg.coef_) print(reg.intercept_)
Output :
array([[ 3.51379258, -3.88713943, -8.6442046 , 24.90308398, 12.45417087, -63.96402292, -15.46790194, 72.47003915, 8.41334485, -30.07026714]])
array([3.85363819])
Fit Ridge Rigression Model
from sklearn.linear_model import Ridge
from sklearn.metrics import mean_squared_error
coes=np.zeros((100,10))
mse=[]
k=0
for i in np.linspace(1,20,100):
clf = Ridge(alpha=i)
clf.fit(sheetx,sheety)
pred=clf.predict(sheetx)
mse.append(mean_squared_error(sheety,pred))
for j in range(10):
coes[k,j]=clf.coef_[0][j]
k+=1
This code fits the Ridge Regression for hundred values of lambda(alpha as per python standards) and stores the value of each coefficient in NumPy array which we will use to plot the variation of parameters with the tuning parameter lambda.
Ploting variation parameters with lambda
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(
for i in range(10):
plt.plot(np.linspace(1,20,100),coes[:,i],label='x'+str(i))
plt.legend()
plt.show()
Output:
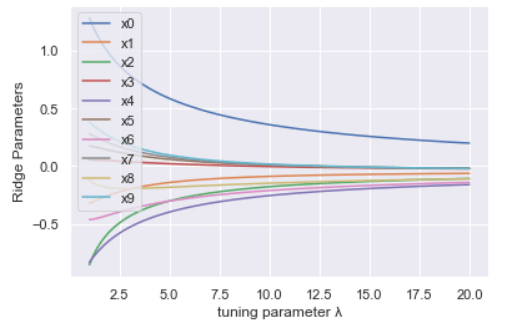
As we can see with increase lambda value parameters are moving towards zero. This essentially reduces the variance of model but increases the bias which can be seen from increasing train error.
Plotting MSE with lambda
plt.plot(np.linspace(1,20,100),mse)
plt.xlabel('tuning parameter λ')
plt.ylabel('Mean Square Error')
plt.show()
Output:
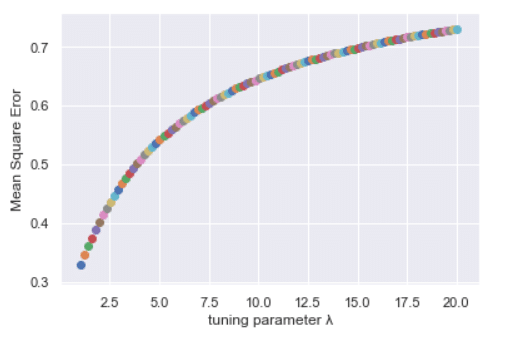
Even though Ridge regression serves the purpose but the obvious disadvantage with Ridge is that parameters tends to zero but never actually touches zero. This may not be a problem in terms of prediction but when it comes to the interpretability of the model this poses the problem.
This is where Lasso comes into picture..
Lasso Regression in Python
Lasso Regression is an addition of l1 norm to RSS equation which now looks like..
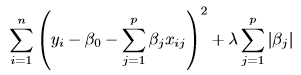
Let’s write code for Lasso regression and visualise it.
from sklearn.linear_model import Lasso
mse=[]
coes=np.zeros((100,10))
k=0
for i in np.linspace(0.01,0.4,100):
clf = Lasso(alpha=i)
clf.fit(sheetx,sheety)
pred=clf.predict(sheetx)
mse.append(mean_squared_error(sheety,pred))
for j in range(10):
coes[k,j]=clf.coef_[j]
k+=1
plt.plot(np.linspace(0.01,0.4,100),mse)
plt.xlabel('tuning parameter λ')
plt.ylabel('Mean Square Eror')
plt.show()
for i in range(10):
plt.plot(np.linspace(0.01,0.4,100),coes[:,i],label='x'+str(i))
plt.xlabel('tuning parameter λ')
plt.ylabel('Ridge Parameters')
plt.legend(loc='upper right')
plt.show()
Output:
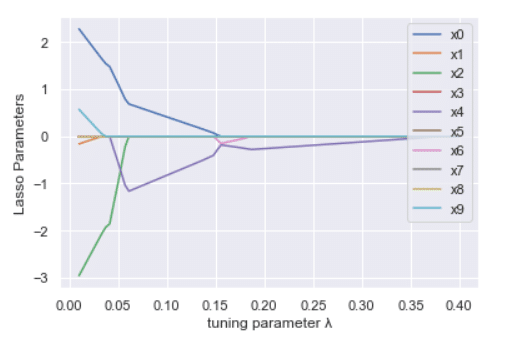
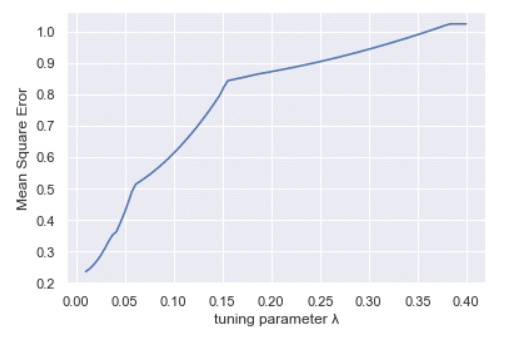
Lasso basically overcome the disadvantage of Ridge regression which we discussed earlier. You can notice that from both the graphs for Ridge and Lasso in which different parameters are plot against hyperparameter lambda. Parameters in Ridge tends towards zero whereas parameters in Lasso actually approaches zero. Which indicates that Lasso can be actually used in feature selection as well apart from regularisation. Reason for this is the containing surface for lasso as shape edges whereas Ridge containing surface is smooth. In smooth surface, it is practically impossible to reach exact optimum point theoretically it can be reached in infinite iterations.
Elastic Net Regression in Python
Elastic Net Regression combines the advantage of both Ridge and Lasso Regression. Ridge is useful when we have a large number of non zero predictors. Lasso is better when we have a small number of non zero predictor and others need to essentially be zero. But we don’t have this information beforehand. We need to cross-validate the result to choose the best model. But we can go for a combination of both instead.
Here is the code for Elastic Net Regression and visualisation of the result.
from sklearn.linear_model import ElasticNet
mse=[]
coes=np.zeros((100,10))
k=0
for i in np.linspace(0.01,0.4,100):
clf = ElasticNet(alpha=i)
clf.fit(sheetx,sheety)
pred=clf.predict(sheetx)
mse.append(mean_squared_error(sheety,pred))
for j in range(10):
coes[k,j]=clf.coef_[j]
k+=1
plt.plot(np.linspace(0.01,0.4,100),mse)
plt.xlabel('tuning parameter λ')
plt.ylabel('Mean Square Eror')
plt.show()
for i in range(10):
plt.plot(np.linspace(0.01,0.4,100),coes[:,i],label='x'+str(i))
plt.xlabel('tuning parameter λ')
plt.ylabel('Ridge Parameters')
plt.legend(loc='upper right')
plt.show()
Output:

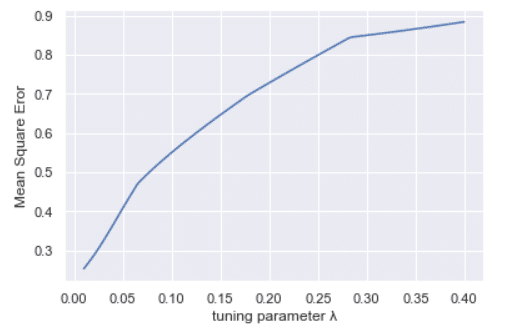
Observe the difference in each of the methods, how differently it is performing from the visualization graphs.
Hope you got some insights into the Regularization methods and when to use which. Will be coming up with more exciting and less talked about topics soon.
Leave a Reply