Handling Missing Data Using Pandas
 By Kunal Gupta
By Kunal GuptaHello everyone, In this tutorial, we’ll be learning about how we can handle missing value or data in a dataset using the Pandas library in Python which allows us to manipulate, analyze data using high performance and easy to use data structures. In this tutorial, we shall see one of the most common uses of this library in handling missing data in a dataset. Let us start this tutorial by seeing what actually is missing data and how it can affect the end results.
Missing data and its effects
Missing values in the data are those that do not provide any information about an attribute and we don’t know their values because they are not actually present or are not calculated or left out during data collection. These values are represented by None(an object that simply defined an empty value or that no data is specified) or NaN(Not a Number, a floating-point representation of missing or null value).
Incorporating Missing data into a machine learning model or neural nets can decrease their accuracy by a great amount. These values are not desirable and we need to remove them or replace them with a value that is not going to affect our models much.
Let us move forward by checking and then do proper operations on the null values.
Checking for Null Values in a dataset using pandas
Let us create a data frame using random real numbers and assign some NaN values in it using np.nan. For simplicity, we have replaced all negative values to NaN.
data=pd.DataFrame(np.random.randn(5,5),index='A B C D E'.split(), columns='F G H I J'.split()) data[data<0]=np.nan print(data)
Checking null values using isna() and isnull()
These two functions work the same and will return True if the value is missing or Null otherwise False.
print("Output of isna()\n", data.isna())
print("\nOutput of isnull()\n", data.isnull())

Checking null values using notna() and notnull()
These functions are just the reverse of the isna() and isnull(). They will return True if the value is other than null otherwise False.
print("\nOutput of notna()\n",data.notna())
print("\nOutput of notnull()\n",data.notnull())

But if we have a large dataset we are not going to see True or False rather we may require a total number of null values in each column or row. For that, we can use any of the above functions with sum(). Let us see how we can calculate the total no. of null values in a column and try to do the same for rows.
print("\nTotal null value in columns\n", data.isnull().sum(axis = 0))

Working of above code
True will return 1 and False will return 0, Therefore calling sum() after isnull() will give the sum of True(1) and False(1). For example in the first column ‘F’ we have 0+1+1+1+0 = 3. Also, note that axis =0 is for columns and axis = 1 is for rows.
Handling Null Values in a dataset
We have discussed how to get no. of null values in rows and columns. Now we will apply various operations and functions to handle these values.
Filling missing values using fillna()
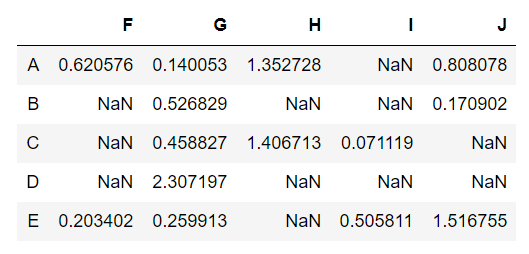
We can fill the NaN values with any value we want using the fillna(). Let us fill all the NaN values with 1.
print('Filling null values with 1\n',data.fillna(1))
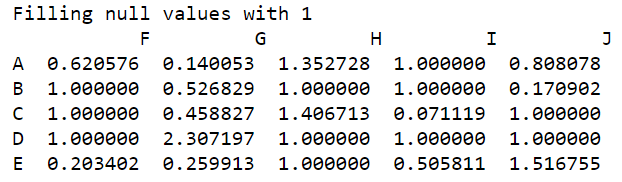
We can also fill null values in any particular column with a specified operation like mean() for example, let us change all null values in column ‘F’ with the mean of all defined values of that column. For this, we will use the value argument.
data['F'].fillna(value=df['F'].mean(),inplace=True) print(data)
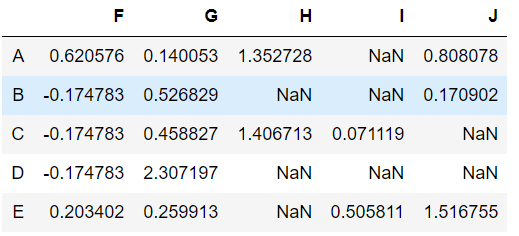
Filling missing values using replace()
This is another function that lets us replace values with the ones that we define. Let us Replace all np.nan values of column ‘I’ with the value 0.
data['I'].replace(to_replace = np.nan, value = 0, inplace==True) data
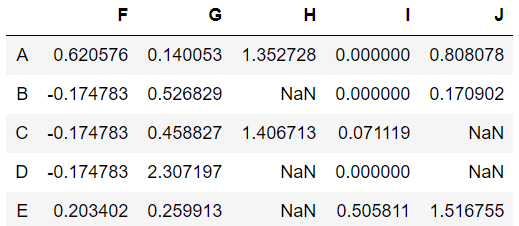
Try to play with these functions and see changes in the data.
Deleting columns or rows with null values using dropna()
Sometimes some columns are not valuable and contain lots of null values which just increase memory consumption and increase complexity so we just remove them from our dataset. For example, In the data frame that we have after replacing and filling some NaN values, we see that still, columns ‘H’ and ‘J’ have some null values. In column ‘H’ we have 3 null values out of 5 so let us delete that whole column using dropna().
data.dropna(how='any',axis=1,thresh=3)
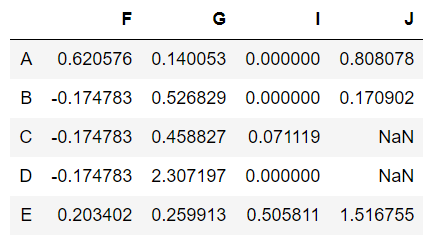
Parameters:
- how – Determine when row or column should be removed based on the presence of null values.
- axis – 1 for column and 0 for row
- thresh – number of non-null values that should be present.
Now we have a dataset that has still some null value. Try to remove them by any of the methods that we have discussed all throughout this tutorial.
We hope you like this tutorial and if you have any doubts feel free to ask in the comment tab below.
You may like to read.
There also is the function pandas.concat().
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.concat.html