Feature Importance In Machine Learning using XG Boost
 By Aumkar M Gadekar
By Aumkar M GadekarOften, in machine learning, it is important to know the effect of particular features on the target variable. Sometimes, features might be correlated or they may not have an impact on the target variable. Feature selection helps in speeding up computation as well as making the model more accurate.
You may have already seen feature selection using a correlation matrix in this article. Here, we look at a more advanced method of calculating feature importance, using XGBoost along with Python language. To read more about what XGBoost is and how it works, refer here.
Feature Selection using XGBoost in Python
Decision Tree-based methods like random forest, xgboost, rank the input features in order of importance and accordingly take decisions while classifying the data. This
The dataset that we will be using here is the Bank marketing Dataset from Kaggle, which contains information on marketing calls made to customers by a Portuguese Bank. You can find the dataset here.
The dataset consists of 17 columns. These include 16 features which describe the following :
- Information about the customer such as age, job, marital status, bank balance, etc.
- Information about the marketing call such as the day and date and duration of the call, etc.
The 17th column is the target variable, ‘deposit’ which is a binary variable. ‘Yes’ indicates the call was successful and a deposit account was created, while ‘No’ indicates the customer rejected the offer. This is the variable that you have to predict.
So, let’s get started with the code!
First, we read in the data.
import pandas as pd
import numpy as np
data=pd.read_csv('bank.csv')
data.head()

As can be seen, a lot of attributes are categorical/string values. Thus, we use label encoding to convert them into numerical values. Below is the Python code:
from sklearn.preprocessing import LabelEncoder encoder=LabelEncoder() data['job']= encoder.fit_transform(data['job']) data['marital']=encoder.fit_transform(data['marital']) data['default']=encoder.fit_transform(data['default']) data['housing']= encoder.fit_transform(data['housing']) data['loan']= encoder.fit_transform(data['job']) data['contact']= encoder.fit_transform(data['contact']) data['month']= encoder.fit_transform(data['month']) data['education']= encoder.fit_transform(data['education']) data['poutcome']= encoder.fit_transform(data['poutcome']) data['deposit']= encoder.fit_transform(data['deposit']) data.head()

Now, the values have been converted to numbers and the dataset is ready for processing. We split the data frame into input features (X) and the output variable (Y).
X=data[['age', 'job', 'marital', 'education', 'default', 'balance', 'housing','loan', 'contact', 'day', 'month', 'duration', 'campaign', 'pdays', 'previous', 'poutcome']] Y=data['deposit']
You will need to install xgboost using pip, following you can import and use the classifier. The classifier trains on the dataset and simultaneously calculates the importance of each feature.
from xgboost import XGBClassifier from matplotlib import pyplot as plt classifier = XGBClassifier() classifier.fit(X, Y) print(classifier.feature_importances_)
You can visualize the scores given to the features using matplotlib’s barplot.
from matplotlib.pyplot import figure figure(figsize=(15, 4.5), dpi=80,) plt.bar(X.columns,model.feature_importances_) plt.show()
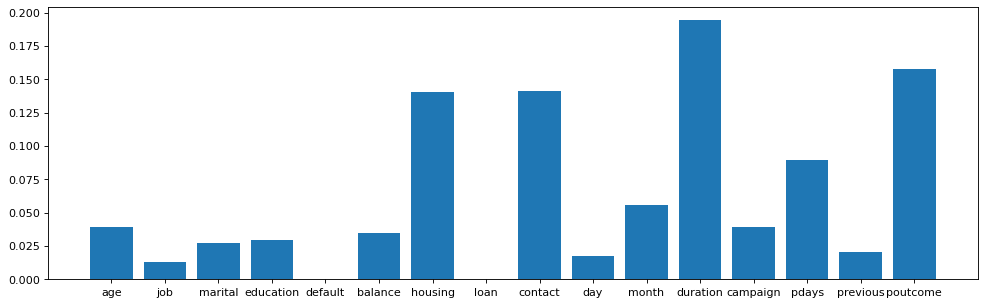
We can now easily see which features are most important in determining the output. The ‘duration’ of the call and the ‘poutcome’ – which stands for the previous outcome(the outcome of the previous call(s) ) are the two most dominant features.
Thus, we can now use this information to select the appropriate features for designing our machine learning model.
Leave a Reply