How to build a Feed Forward Neural Network in Python – NumPy
 By Abhilash Bandla
By Abhilash BandlaThis Python tutorial helps you to understand what is feed forward neural networks and how Python implements these neural networks.
build a Feed Forward Neural Network in Python – NumPy
Before going to learn how to build a feed forward neural network in Python let’s learn some basic of it.
Definition :
The feed forward neural network is an early artificial neural network which is known for its simplicity of design. The feed forward neural networks consist of three parts. Those are:-
- Input Layers
- Hidden Layers
- Output Layers
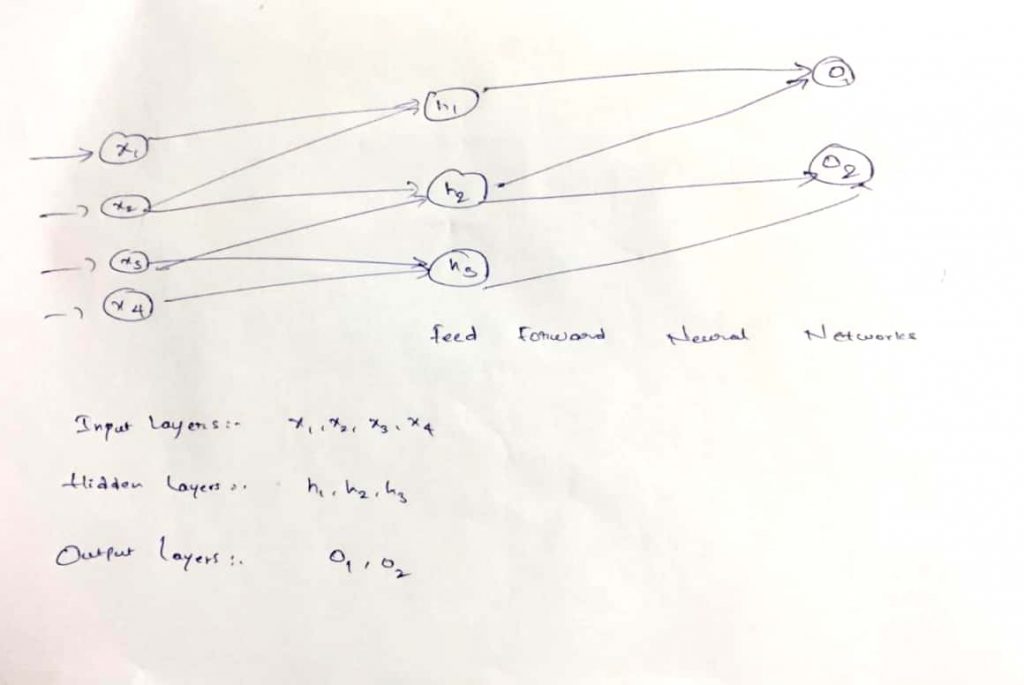
General feed forward neural network
Working of Feed Forward Neural Networks
These neural networks always carry the information only in the forward direction. First, the input layer receives the input and carries the information from the input layer to the hidden layer. Then the hidden layer undergoes some activation functions and the value computed from the activation function acts as input to the output layer. Again, the output layer undergoes some activation functions and the value computed from those activation functions will be the final output.
Every hidden layer and output layer undergoes activation function and gets output from the activation function. But, what is the activation function?
Definition :
Activation functions are one of the important features of artificial neural networks. Activation functions decide which neuron should be activated or not. This activation function also decides whether the information the neuron receives is relevant or should be ignored.
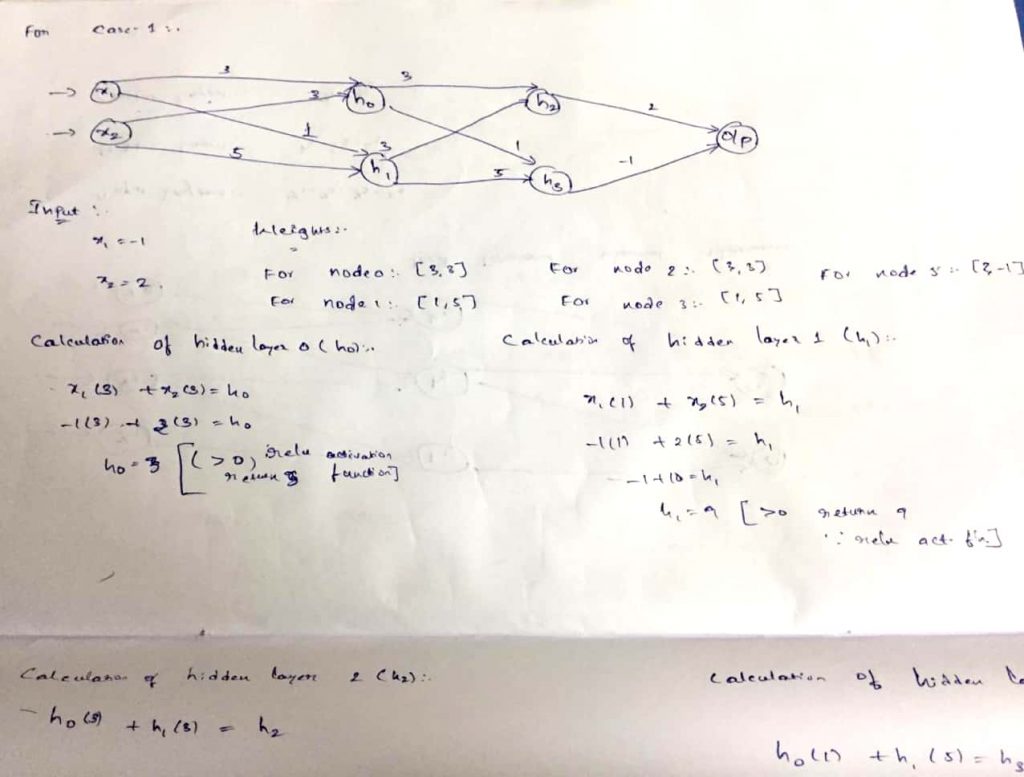
Feed forward neural network for input 1
Advantages :
- Performs non-linear transformation for the hidden layers and output layers.
- Non-Linear transformation helps the neural network model to perform complex tasks.
- Some examples of the complex tasks are language translations, image classifications etc.,
If activation functions are not used, the neural network model will not perform such complex tasks.
Examples of activation functions :
Sigmoid, ReLu, Softmax etc.,

Computation for the input 1
Implementation of Feed Forward in Python using NumPy
Source Code :
import numpy as np
def relu(n):
if n<0:
return 0
else:
return n
inp=np.array([[-1,2],[2,2],[3,3]])
weights=[np.array([3,3]),np.array([1,5]),np.array([3,3]),np.array([1,5]),np.array([2,-1])]
for x in inp :
node0=relu((x*weights[0]).sum())
node1=relu((x*weights[1]).sum())
node2=relu(([node0,node1]*weights[2]).sum())
node3=relu(([node0,node1]*weights[3]).sum())
op=relu(([node2,node3]*weights[4]).sum())
print(x,op)
Explanation :
In the above code, three input examples are present. In every example, two input layers are present and four hidden layers are present (node0, node1, node2, node3) and one output layer is present. Each hidden layer and output layer uses relu activation function. If the value computed using this activation function is less than zero then the hidden layer or output of the function is zero else, the value will be the same as the computed value.
Output :-
Case -1:-
Input-1 : -1 Input-2 : 2 Output : 24
Case -2:-
Input-1 : 2 Input-2 : 2 Output : 72
and Case -3:-
Input-1 : 3 Input-2 : 3 Output : 108
You can also read,
Leave a Reply