A Machine Learning Model In Python To Predict Employee Churn
 By Abhishiek Bhadauria
By Abhishiek BhadauriaIn this tutorial, we will learn how to build a machine learning model in python to predict employee churning rate. To achieve this, we will have to import various modules in python. We will be using PyCharm IDE To Code.
Modules can be directly installed through “pip install” command or we can install anaconda and make it as our project interpreter IDE in PyCharm.
We will be importing Pandas to import dataset, Matplotlib and Seaborn for visualizing the Data, sklearn for algorithms,train_test_split for splitting the dataset in testing and training set, classification report and accuracy_score for calculating accuracy of the model.
Also, read: Predict Disease Using Machine Learning with Python Using GUI
We will be using random forest classifier to train and test the model.
Python Machine Learning Model To Predict Employee Churn
Now our first step will be to import dataset. To download the dataset used in this tutorial click the link here. After that import the dataset we will be using pandas read_csv() function to import dataset. Because our dataset already contains metadata(i.e. Heading names) there is no need to give names attribute value in read_csv(). Following code implements it:-
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
df=pd.read_csv("HR_comma_sep.csv")
The next step will be to see how does your dataset looks like and we will also check that if it contains any null values. So to check for null values, we will use isnull().sum() function.Following code implements it:-
print(df.head()) print(df.shape) print(df.describe()) print(df.isnull().sum())
The output of the above code snippet will be:
satisfaction_level last_evaluation ... Departments salary
0 0.38 0.53 ... sales low
1 0.80 0.86 ... sales medium
2 0.11 0.88 ... sales medium
3 0.72 0.87 ... sales low
4 0.37 0.52 ... sales low
[5 rows x 10 columns]
(14999, 10)
satisfaction_level last_evaluation ... left promotion_last_5years
count 14999.000000 14999.000000 ... 14999.000000 14999.000000
mean 0.612834 0.716102 ... 0.238083 0.021268
std 0.248631 0.171169 ... 0.425924 0.144281
min 0.090000 0.360000 ... 0.000000 0.000000
25% 0.440000 0.560000 ... 0.000000 0.000000
50% 0.640000 0.720000 ... 0.000000 0.000000
75% 0.820000 0.870000 ... 0.000000 0.000000
max 1.000000 1.000000 ... 1.000000 1.000000
[8 rows x 8 columns]
satisfaction_level 0
last_evaluation 0
number_project 0
average_montly_hours 0
time_spend_company 0
Work_accident 0
left 0
promotion_last_5years 0
Departments 0
salary 0
dtype: int64
After This we take a look at departments variable, it contains some redundant data. Also, we will replace the ‘left’ attribute with ‘Attrition’.Following code implements it:-
df=df.rename(columns={"left":"Attrition"})
print(df.Departments.value_counts())
Output:
sales 4140 technical 2720 support 2229 IT 1227 product_mng 902 marketing 858 RandD 787 accounting 767 hr 739 management 630 Name: Departments, dtype: int64
As we can see from the above output that departments attribute contain some redundant data. As a result of this, we will combine ‘technical’, ‘support’ and ‘IT’ under the new term ‘techs’.Following Code Implements It:-
df[["Departments"]]=df[["Departments"]].replace("support","techs")
df["Departments"]=np.where(df["Departments"]=="IT","techs",df["Departments"])
df["Departments"]=np.where(df["Departments"]=="technical","techs",df["Departments"])
print(df.Departments.value_counts())
Output:
techs 6176 sales 4140 product_mng 902 marketing 858 RandD 787 accounting 767 hr 739 management 630 Name: Departments, dtype: int64
In the next step, we will visualize the data by plotting various attributes as bar graphs. Following Code Implements It:-
sns.countplot(df.Attrition) plt.show() pd.crosstab(df.Departments,df.Attrition).plot(kind='bar') plt.show() pd.crosstab(df.salary,df.Attrition).plot(kind='bar') plt.show() pd.crosstab(df.time_spend_company,df.Attrition).plot(kind='barh') plt.show()
Output for the above code snippet is:
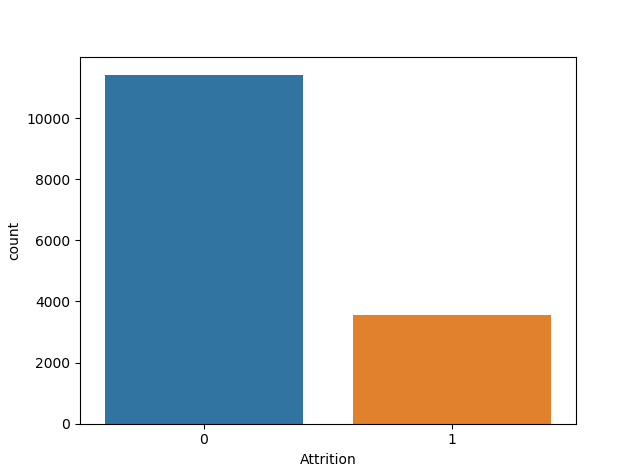
1. A plot of count vs attrition
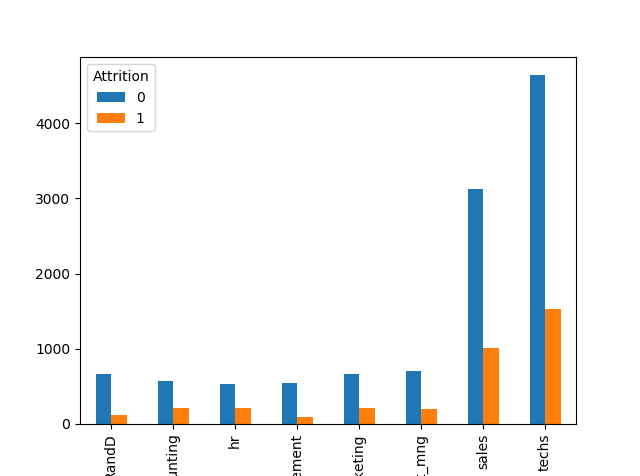
2. A plot of attrition count vs departments

3. A plot of attrition count vs salary
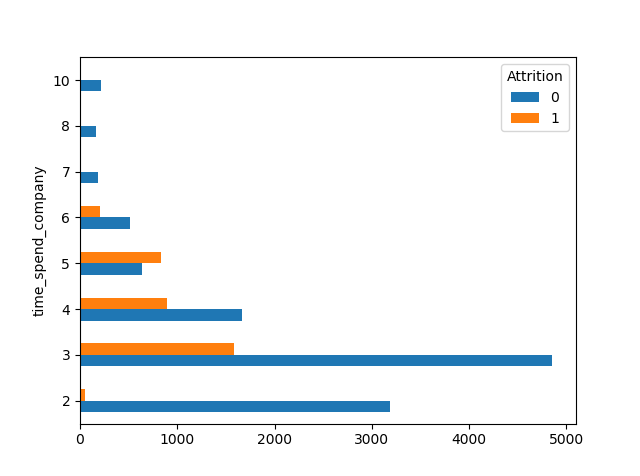
4. A plot of attrition count vs time_spend_company
Looking at the above plots, we can infer:
- People leaving the company(1) is smaller than non-leavers(0).
- Turnover is varying. Clearly ‘techs’ people are among the largest attritioners followed by sales.
- People with 3 yrs. of experience tend to leave often.
- The low salaried person often tends to leave the company.
As the ‘Departments’ and ‘salary’ contain text(non-numerical value) we need to create dummy variables. Following Code Implements It:-
dum1=pd.get_dummies(df.Departments,prefix="Departments").iloc[:,1:] dum2=pd.get_dummies(df.salary,prefix="salary").iloc[:,1:] df=pd.concat([df,dum1,dum2],axis=1) df=df.drop(["Departments","salary"],axis=1) plt.show()
Here we have created two dummy variables dum1 and dum2 and concatenated into the original dataframe. As a result, we will have to drop the original variables ‘Departments’ and ‘salary’ from the dataframe.
Output:

Now we will slice the data-frame into two parts-X and Y.X will be an array containing all the attributes except the target variable while Y is the array of the target variable. Also, we will split the X and Y dataset into the train and test split parts for training and testing. Following code implements it:-
array=df.values X=array[:,0:16] Y=array[:,16] from sklearn.model_selection import train_test_split X_train,X_test,Y_train,Y_test=train_test_split(X,Y,test_size=0.3,random_state=100)
Now comes the most exciting part of which we all have been waiting for. We will use random forest classifier algorithm to train the model. We will later predict the values of the Y_test set. Following code implements it:-
from sklearn.ensemble import RandomForestClassifier cl=RandomForestClassifier(n_estimators=100,criterion='entropy',random_state=100) cl.fit(X_train,Y_train) Y_pred=cl.predict(X_test)
In the last part, we will print the classification report and the accuracy score of the model. Following code implements it:-
from sklearn.metrics import classification_report,accuracy_score
print(classification_report(Y_test,Y_pred))
print("Accuracy Is:",accuracy_score(Y_test,Y_pred)*100)
The output of the following code segment is:
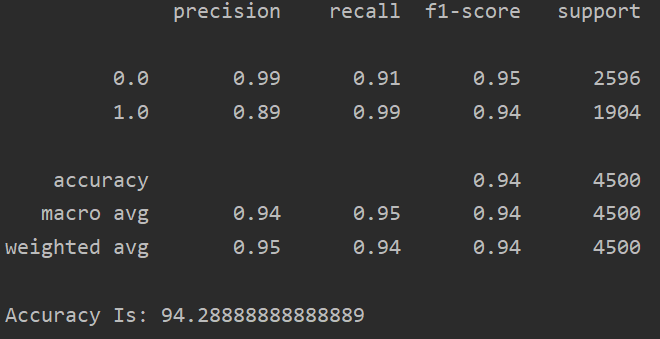
We have finally built a machine learning model to predict employee churn rate.
Thank You
Moreover please don’t forget to check the following articles:
It’s so easy to grasp.
Thank You!