World Cup cricket winning prediction using Machine learning in Python
 By Pranit Sawant
By Pranit SawantIn this tutorial, we will learn about how to use machine learning to predict the winner of any tournament. In this article, we will be particularly focusing on the cricket World Cup winner prediction. We are using data before 2019 which we are going to use to predict the 2019 world cup winner. We can follow similar steps for updated data to predict the winner of the world cup of that year.
We will build a machine-learning model using the following steps
- Importing required libraries
- Loading data files
- Perform Exploratory data analysis
- Feature Engineering
- Building Machine learning models and comparing their performance
- Evaluating model performance
Introduction to Dataset
Dataset link
download dataset cricket world cup winner prediction zip file
We have a total of 10 teams who played in the World Cup
We have the following four .csv files.
- World Cup 2019 Dataset: Information about how many times a team qualified for semifinals, played finals won titles, etc.
- Results: The results of the matches between two teams played cricket between 2010 to 2017.
- Icc_rankings: ICC ranking of each team.
- Fixtures: 2019 World Cup timetable including location, Date, etc.
Build a machine-learning model for World Cup cricket winner prediction
Importing required libraries.
import pandas as pd import numpy as np from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression
In the above code pandas we used for creating dataframe objects which are then used for analysis. Numpy we used for data manipulation and analysis. We are importing the train test split to divide data into training and testing sets. Finally, we are importing logistic regression which is the model we use for the prediction of the winner.
To load the files:
WC = pd.read_csv(r'C:\Users\DELL\Desktop\ World Cup 2019 Dataset.csv') R = pd.read_csv(r'C:\Users\DELL\Desktop \results.csv')
We will only focus on results files as we are going to use them to build our machine learning model. We will build a machine learning model using results files and will use that model to predict a winner for World Cup 2019.
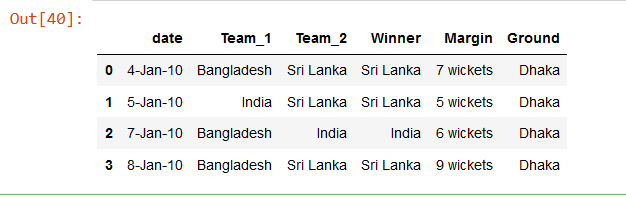
R.head(4)
This will print the first 4 rows of the result file.
Output:
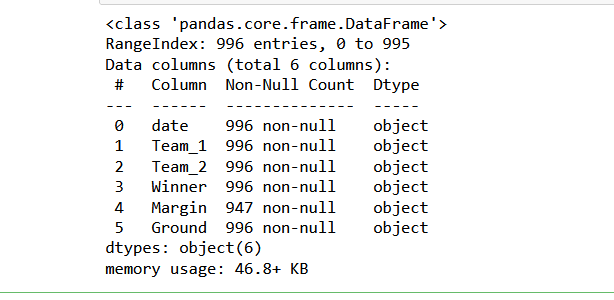
R.info()
This will print some basic information about column name and column type in that file.
Output:
R.isnull().sum()
This will give several null values per column in the data frame.
Output:

Now we have many countries in the result file. But all the countries are not playing in the 2019 World Cup. To avoid taking all the countries and to improve model performance we will simply filter the countries playing in the World Cup in the result data frame. We will do it using the following code.
WC_teams = ['England', ' South Africa', 'West Indies',
'Pakistan', 'New Zealand', 'Sri Lanka', 'Afghanistan',
'Australia', 'Bangladesh', 'India']
team1 = R[R['Team_1'].isin(WC_teams)]
team2 = R[R['Team_2'].isin(WC_teams)]
team = pd.concat((team1,team2))
team.drop_duplicates()
team.count()
In the above code first, we are creating a list of the countries playing in the 2019 World Cup. Then team1 and team2 store data frame objects where the value Team_1 column in the result (R) data frame is in our WC_teams list.
Output:

Now we will drop unnecessary columns in the above data.
df_new = team. drop(['date',' Margin', 'Ground'], axis=1) df_new.head()
Output:
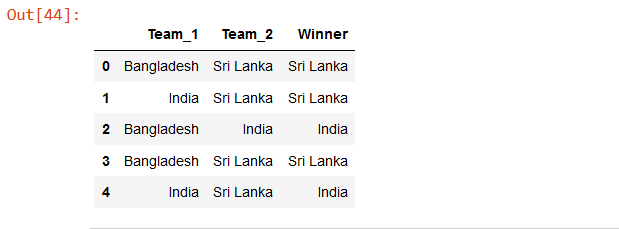
The above code will drop columns named ‘date’,’ Margin’, and ground from the team data frame.
As we are done with filtering now we will convert categorical data in the above data frame into numerical data to use to build a machine learning model.
df_final = pd.get_dummies(df_new,columns=['Team_1', 'Team_2']) df_final=pd.DataFrame(df_final) X = df_final.drop(['Winner'], axis=1) y = df_final["Winner"] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30, random_state=42)
In the above code, we are using the get_dummy method to convert categorical data into numerical. It will create a separate column for each unique value in Team_1 and Team_2 columns. Then we convert get_dummy into a data frame object and then we assign the dependent and independent variables to the X, and y variables respectively.
Finally, we are performing train and test split. With a test size of 30 %. The df_final data frame will look like below:
Output:
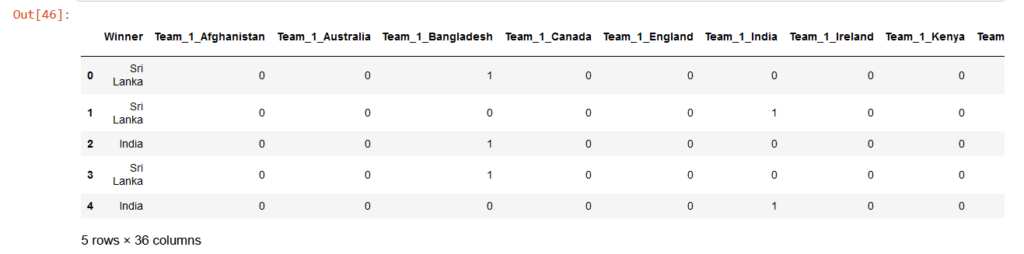
Now to fit the machine learning model.
lr = LogisticRegression()
lr.fit(X_train, y_train)
score = lr.score(X_test, y_test)
print("accuracy: ", '%.2f'%(score))
Output:

In the above code, we first create instance ‘lr’ for the logistic regression model. Then using lr. fit we fit the model to the X_train and y_train set. Then finally we are printing the accuracy of the model.
Now we have built our model. It is time to use it to predict the winner of the 2019 World Cup.
Import the fixtures and ranking files to use those to make predictions
ranking = pd.read_csv(r'C:\Users\DELL\Desktop\icc_rankings.csv') fixture = pd.read_csv(r'C:\Users\DELL\Desktop\fixtures.csv') fixture.head(3)
Output:

Now we will make use of the ranking file to create new columns ‘first_rank’, and ‘second_rank’ which indicate ranking between 1 to 10 for a given team.
fixture.insert(1, 'first_rank', fixture['Team_1'].map(ranking.set_index('Team')['Position']))
fixture.insert(2, 'second_rank', fixture['Team_2'].map(ranking.set_index('Team')['Position']))
fixture = fixture.iloc[:45, :]
fixture.head(30)
We are selecting the first 45 teams only as the total games played in the 10 teams will be 45. And finally displaying the data frame.
Output:
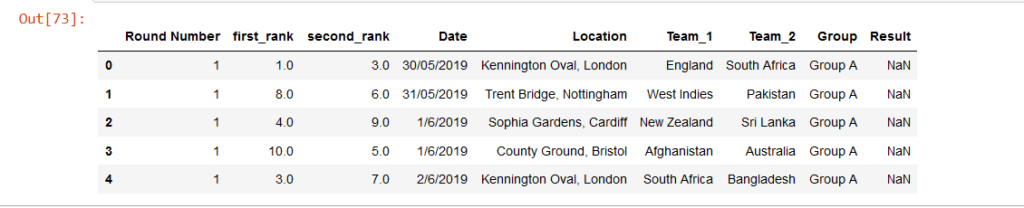
Now based on ranking position we will create a new dataframe that will assign teams in Team_1, Team_2 columns.
predict = []
for index, row in fixture.errors():
if row['first_rank'] < row['second_rank']:
predict.append({'Team_1': row['Team_1'], 'Team_2': row['Team_2'], 'winning_team': None})
else:
predict.append({'Team_1': row['Team_2'], 'Team_2': row['Team_1'], 'winning_team': None})
predict = pd.DataFrame(predict)
backup_predict = predict
predict.head()
Output:
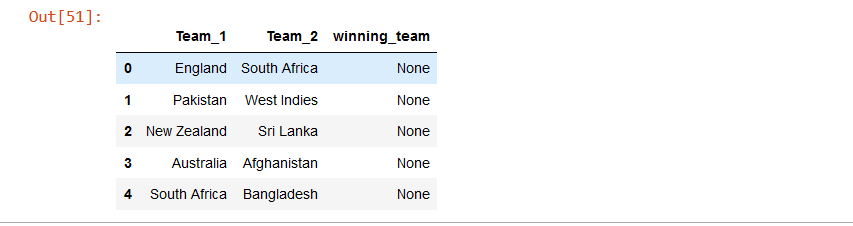
In the above code if the first rank in the fixtures column is less than the second rank then we are assigning Team_1 in the fixtures column to the Team_1 column in the new data frame. And Team_2 to Team_2 column in the new data frame. And vice versa.
See in the above dataset one of the columns is less as compared to model training data. so we need to add one more column we will do it using the following code and will fill the missing values in the new column with 0.
predict = pd.get_dummies(predict, columns=['Team_1', 'Team_2'])
# Add missing columns compared to the model's training dataset
missing_cols = set(df_final.columns) - set(predict.columns)
for c in missing_cols:
predict[c] = 0
predict = predict[df_final.columns]
predict = predict.drop(['Winner'], axis=1)
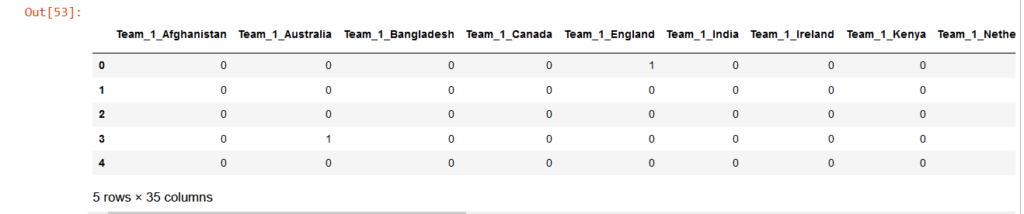
predict.head()
First, we are using the get dummy method while training the model. We are dropping the winner column and we are going to predict.
Output:
Using the build model we will predict a winner for each of the pair of the team
predictions = lr. predict(predict)
for i in range(fixture.shape[0]):
print(backup_predict.iloc[i, 1] + " and " + backup_predict.iloc[i, 0])
if predictions[i] == 1:
print("Winner: " + backup_predict.iloc[i, 1])
else:
print("Winner: " + backup_predict.iloc[i, 0])
print("")
Output:

we are looping through each pair and using the predicted data frame we are printing the winner of the match.
Now based on the above prediction India, New Zealand, England, and Australia are the teams that are likely to qualify for the semifinals.
Let’s store it in a semifinal list in the form of tuples.
semifinal = [('New Zealand', 'India'),
('England', 'Australia')]
Function to predict World Cup winner
Define a function that will predict the winner based on the teams qualifying for the semifinals.
def finalpredict(matches, ranking, final, logreg):
positions = []
for match in matches:
positions.append(ranking.loc[ranking['Team'] == match[0],'Position'].iloc[0])
positions.append(ranking.loc[ranking['Team'] == match[1],'Position'].iloc[0])
pred = []
i = 0
j = 0
while i < len(positions):
dict1 = {}
if positions[i] < positions[i + 1]:
dict1.update({'Team_1': matches[j][0], 'Team_2': matches[j][1]})
else:
dict1.update({'Team_1': matches[j][1], 'Team_2': matches[j][0]})
pred.append(dict1)
i += 2
j += 1
pred = pd.DataFrame(pred)
backup_pred = pred
pred = pd.get_dummies(pred, prefix=['Team_1', 'Team_2'], columns=['Team_1', 'Team_2'])
missing_col = set(final.columns) - set(pred.columns)
for c in missing_col:
pred[c] = 0
pred = pred[final.columns]
pred = pred.drop(['Winner'], axis=1)
# Predict!
predictions = lr.predict(pred)
for i in range(len(pred)):
print(backup_pred.iloc[i, 1] + " and " + backup_pred.iloc[i, 0])
if predictions[i] == 1:
print("Winner: " + backup_pred.iloc[i, 1])
else:
print("Winner: " + backup_pred.iloc[i, 0])
print("")
In the above function what we are doing is we are using all the steps we followed after importing the ranking file in a single function with modification of the while loop. and for loops. This function makes use of the df_final data frame, ranking data frame, logistic regression, and the new data frame we are going to predict.
Now let’s use the above function to predict the winner of the semifinals:
final predict(semi, ranking, df_final, logistics)
Output:

Now we will store these two winners in a list named ‘final’
final = [('India', 'England')]
we will again use the final predict function to predict the winner of the 2023 World Cup.
final predict(final, ranking, df_final, lr)
Output:

So our model says the 2019 World Cup winner is England.
We have seen how to use historical data to build machine-learning models. We have successfully built the model to predict outcomes. We will use the same model and code to predict Winne for the next World Cup with the updated dataset.
Leave a Reply