University Admission Prediction using Keras in Python
 By Om Tejaswini
By Om TejaswiniThis post aims to predict the likelihood of a student being admitted into a university based on some factors. A predictive model is developed using neural networks to do this task in Python.
Code implementation
Import necessary libraries
import pandas as pd import numpy as np from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler import tensorflow as tf from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense
Read the dataset
The dataset can be downloaded using this link:
https://www.kaggle.com/code/harasissingh/university-admission-prediction/input
This dataset contains GRE Score, TOEFL Score, University Rating, SOP(Statement of Purpose), LOR(Letter of Recommendation), CGPA, and Research as features and Chance of Admit as the target.
df = pd.read_csv('AdmissionsData.csv')
df.head()Output:

Data pre-processing and splitting
Serial number column is not required. So, it can be dropped.
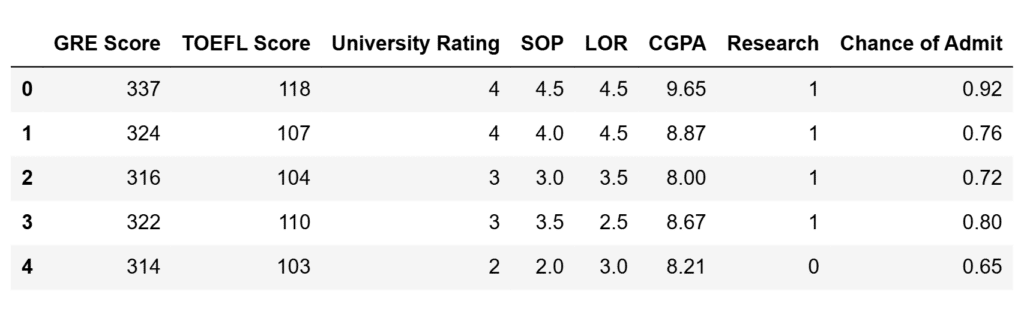
df = df.drop(columns=['Serial No.']) df.head()
Output:
Split the dataset into features and target variables
X = df.drop(columns=['Chance of Admit ']) y = df['Chance of Admit ']
Standardize the features
Standardization means adjusting features such that the mean of the feature is 0 and the standard deviation is 1. With this, we can ensure that our data is normally distributed, which improves the model’s performance.
scaler = StandardScaler() X_scaled = scaler.fit_transform(X)
Split the data into training and testing sets
Split the data set into train and test sets.
Train set: 80%, Test set: 20%
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
Build and compile the model
Use a sequential model. 3 dense layers are used in this model. The first layer is a dense layer with 64 neurons and relu as the activation function, the next hidden layer has 32 neurons and the same relu as the activation function, The Output layer has 1 neuron and uses the sigmoid activation function. While compiling the model mean squared error as the loss function and Adam as the optimizer.
model = Sequential() model.add(Dense(64, input_dim=X_train.shape[1], activation='relu')) model.add(Dense(32, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='mean_squared_error', optimizer='adam', metrics=['mae']) model.summary()
Output:

Train the model
Train the model for 100 epochs.
model.fit(X_train, y_train, epochs=100, batch_size=10, validation_split=0.2, verbose=1)
Output:

Model Evaluation
The model is evaluated on the test set that resulted in a loss of 0.0058 and a mean absolute error (MAE) of 0.0522.
loss, mae = model.evaluate(X_test, y_test)
print(f'Loss: {loss}, Mean Absolute Error: {mae}')Output:

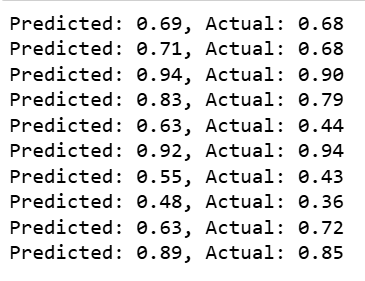
Predicting on test data:
y_pred = model.predict(X_test)
for i in range(10):
print(f'Predicted: {y_pred[i][0]:.2f}, Actual: {y_test.iloc[i]:.2f}')Output:
Leave a Reply