ORC file Reading using Pandas in Python
 By Isha Bansal
By Isha BansalHey fellow Python coder! In this tutorial, we will be covering what ORC files are and how to read ORC files using the Pandas library in Python programming. In this tutorial, we will be covering the following topics:
- Introduction to ORC files
- Advantages of working with ORC files
- Creating ORC files using Python programming
- Reading ORC files stored locally using Python programming
Introduction to ORC (Optimized Row Columnar) files
ORC files organize data into rows and columns, similar to tabular data. But unlike CSV or other tabular formats, it stores data in a columnar format. Which simply means that values from each column are stored together. This ensures that these types of files store data using reduced space and helps in performing reading and writing actions quicker and more efficiently.
ORC files have several advantages, some are listed as follows:
- Since data is stored in a columnar format, the queries are based on only the columns, making operations quicker.
- As these types of files, store data in a compressed form, it leads to faster query processing.
- It also allows appending new data to already created ORC files which makes it easier for the developer to modify data without the need to overwrite or redo the data all over again.
To work with ORC files in Python, we will make use of the PyArrow library. This library comes with functions to work with structured data at the memory level. This library works well along with many other popular Python libraries such as Pandas, NumPy, Dask, and TensorFlow.
To install PyArrow you can use this command:
pip install pyarrow
Creating ORC files using Python programming
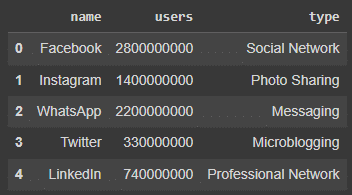
This section will cover the creation of a simple ORC file using the code snippet below. For this tutorial, we will use the concept of “SOCIAL MEDIA APPLICATIONS” and create an ORC file regarding the dataset mentioned below.
socialMediaData = [
{"name": "Facebook", "users": 2800000000, "type": "Social Network"},
{"name": "Instagram", "users": 1400000000, "type": "Photo Sharing"},
{"name": "WhatsApp", "users": 2200000000, "type": "Messaging"},
{"name": "Twitter", "users": 330000000, "type": "Microblogging"},
{"name": "LinkedIn", "users": 740000000, "type": "Professional Network"}
]To convert the dataset to the ORC file, we will make use of the PyArrow library. Have a look at the code snippet below.
import pandas as pd import pyarrow as pa import pyarrow.orc as orc socialMedia_DataFrame = pd.DataFrame(socialMediaData) socialMedia_PyArrowTable = pa.Table.from_pandas(socialMedia_DataFrame) orc.write_table(socialMedia_PyArrowTable, 'Social_Media.orc')
We will convert the dictionary data into a pandas data frame, then convert it to a PyArrow table, and finally write the table into an ORC file. This code will create a Social_Media.orc file in your local system.
Reading ORC files stored locally using Python programming
To read the tabular data from the ORC file, we will make use of the read_table function. Next, we will convert the ORC table to a data frame for easy readability.
socialMedia_ORCTable = orc.read_table('Social_Media.orc')
socialMedia_DF = socialMedia_ORCTable.to_pandas()When printed the data frame in Google Colab the resulting tabular data that gets displayed on the screen is as follows:
That’s it for this tutorial. Now you have learned how to create and read an ORC file using Pandas in Python programming. Thank you for reading!
Also Read:
- SAS Files Reading Using Pandas in Python
- Scrape HTML Table from a web page or URL in Python
- How to create a table, insert data, and fetch data in Oracle Database using Python
- How to delete a table from Oracle Database in Python
Happy Learning!
Leave a Reply